Reporting Date: Septemger. 28, 2024
두 연속형 변수들 간의 연관성을 측정하는 데 사용되는 상관계수에 대해 다루고자 한다.
(4장 두 변수 자료의 요약과 이어지는 내용이다.)
목차두 변수의 공분산 구하는 과정
1. 피어슨의 적률상관계수
2. 스피어만의 순위상관계수
⌎사례: 소득과 지출 사이에는 상관관계가 있는가?
두 변수의 공분산 구하는 과정
1. 각 데이터에서 평균을 빼서, 두 변수의 편차를 각각 구한다.

2. 두 변수 각각의 편차를 곱한 후 합산하는 방식이다.

더한 값에서 데이터 개수 n – 1 로 나눈 값이 표준 공분산이 된다.
3. 공분산의 값은 – ∞ ~ + ∞ 사이에 존재한다.

공분산은 두 변수 간의 선형 관계를 나타내기 때문에,
그 값은 음의 무한대에서 양의 무한대까지의 범위를 가질 수 있다.
공분산이 양수이면 두 변수는 같은 방향으로 움직이고,
음수이면 반대 방향으로 움직인다.
두 값의 편차를 구하고, 이를 공분산으로 계산하는
과정은 Z–분포와 일부 유사할 수 있다.
Z–분포는 표준화를 기반으로 하고, 상관계수도
공분산을 표준화하는 과정이 있기 때문에 연결이 가능하다.
다만, Z–분포는 정규 분포의 표준화 개념을 나타내고,
상관계수는 두 변수 간의 관계를 표준화하여 설명하는 것이므로
서로 다른 개념이라는 점을 주의해야 한다.
공분산은 단위가 포함된 값이다.
서로 다른 단위를 가진 변수들 간의 공분산은
크기나 해석에서 어려움이 있을 수 있다.
예를 들어, 키와 몸무게의 공분산은
그 자체로 의미를 이해하기 어렵다.
이를 보다 쉽게 해석하기 위해, 공분산을 표준화하여
단위를 제거한 새로운 값인 상관계수를 사용한다.
단위를 제거하기 위해 공분산을 각각의 표준편차로 나눈다.
이 과정에서 각 변수의 단위가 없어지고,
–1 ~ +1 사이의 범위를 갖는다.
결과적으로 이것을 피어슨 적률상관계수라고 한다.
피어슨의 적률상관계수
(Pearson correlation coefficient)
둘 다 피어슨 상관계수를 나타내지만,
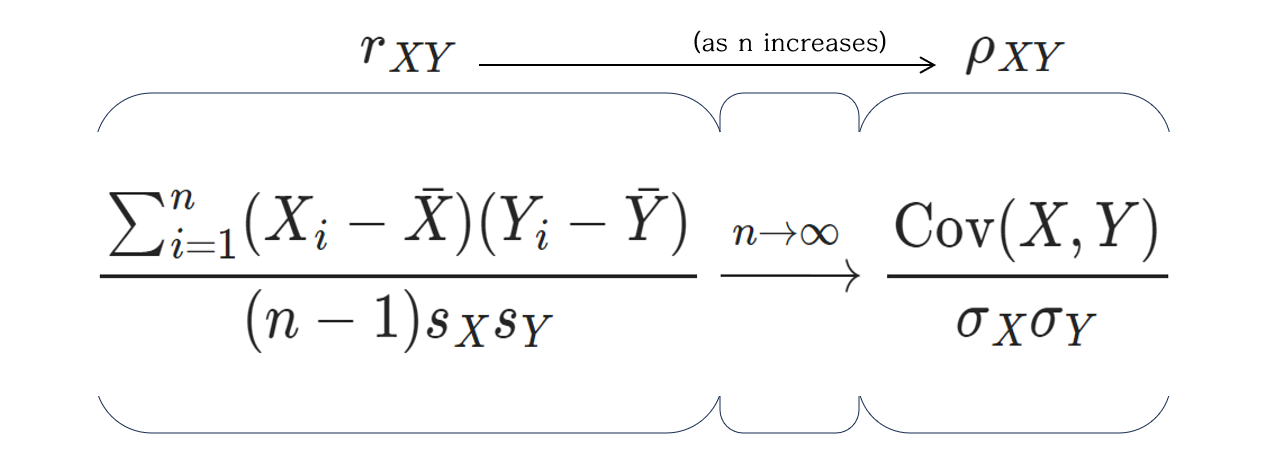
왼쪽은 표본을 통해 추정한 상관계수이고,
오른쪽은 모집단의 상관계수를 의미한다.
표본상관계수 r을 이용하여,
모상관계수 ρ에 대한 가설검증을 할 수 있다.
귀무가설에 대한 검정통계량은 아래와 같은 통계량으로서
이는 귀무가설 하에서 자유도 n – 2인 T–분포를 따른다.

더 일반적인 상관계수에 대한 귀무가설 검정을 수행하려면,
피셔의 Z–변환을 이용할 수 있다.
스피어만의 순위상관계수
(Spearman's Rank Correlation Coefficient)
두 변수 간의 비선형 관계를 측정하는 방법으로,
각 데이터의 순위를 사용하여 상관관계를 계산한다.
이는 데이터가 서열형(순위) 혹은 비모수적일 때 유용하며,
피어슨 상관계수와 달리 데이터의 분포에 대해 가정하지 않는다.


사례
소득과 지출 사이에는 상관관계가 있는가?
import os
import pandas as pd
# 상대 경로 설정
file_path = os.path.join('data', 'Student.csv')
# CSV 파일 읽기
Student = pd.read_csv(file_path)
# 데이터 확인
Student.head(10)
먼저, 산점도를 통해 데이터 분포의 전체적인 형태를 시각화한다.
import matplotlib.pyplot as plt
plt.plot('Income', 'Expense', # 소득, 지출
'o', # 점의 형태: 원형
color = 'black', data = Student)
plt.xlabel('Income')
plt.ylabel('Expense')
plt.scatter('Income', 'Expense',
data = Student)
plt.xlabel('Income')
plt.ylabel('Expense')
신뢰구간, 회귀직선, 히스토그램이 추가된 산점도를 그린다
import seaborn as sns
sns.jointplot(x = 'Income', y = 'Expense',
data = Student, kind = "reg")
산점도 행렬 출력하기
sns.pairplot(Student.iloc[:,1:4])
g = sns.PairGrid(Student.iloc[:,1:4])
g.map_upper(sns.scatterplot)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw = 3)

정방행렬의 형태로 피어슨의 상관계수 출력
Student.iloc[:,1:4].corr(method='pearson')
전반적으로, 모든 변수들 간의 상관계수가 0.5 이상으로 비교적 높다.
두 변수 수입과 지출 간의 모상관계수가 0인지를 검정한다.
from scipy.stats import pearsonr
pearsonr(Student.Income, Student.Expense)
표본 상관계수는 0.681로 비교적 높게 나타났으며,
p–값은 0.002(0.2%)로 매우 낮아 귀무가설을 기각할 수 있다.
따라서, 모상관계수가 0이 아니라고 결론지을 수 있다.
상관계수와 p–값을 함께 출력한다.
# !pip install pingouin
import pingouin as pg
Student.iloc[:,1:4].pairwise_corr(method='pearson').round(3)
상관계수행렬을 그래프로 그린다
corrMatrix = Student.iloc[:,1:4].corr(
method = 'pearson')
import seaborn as sns
sns.heatmap(corrMatrix,
annot = True) # 그림 위 수치 표시
편상관계수
(Partial Correlation Coefficient)
두 변수 간의 상관관계를 분석할 때,
특정 다른 변수의 영향을 통제(고정)한 후의 상관관계를 나타내는 지표.
이를 통해 변수들 간의 순수한 연관성을 파악할 수 있다.
사례
변수인 나이를 통제했을 때, 기능과 디자인에 대한 만족도 간에 상관관계가 있는가?
import os
import pandas as pd
# 상대 경로 설정
file_path = os.path.join('data', 'Satis.csv')
# CSV 파일 읽기
Satis = pd.read_csv(file_path)
# 데이터 확인
Satis.head(10)
1 ~ 3번째 열까지의 상관계수를 구하고,
그 값을 소수점 셋째 자리로 반올림하여 출력
Satis.iloc[:,1:4].corr().round(3)
두 변수 간의 피어슨 상관계수와 p–값 출력
from scipy.stats import pearsonr
pearsonr(Satis.Satis1, Satis.Satis2)
p–값이 0.0005(0.05%)이므로, 귀무가설을 기각할 수 있다.
1 ~ 3열까지의 데이터에 대해 편상관계수 출력
import pingouin as pg
Satis.iloc[:,1:4].pcorr().round(3)
Age – Satis2 (0.9): 매우 강한 양의 상관관계가 있으며,
Age – Satis1 (-0.0): 0에 가까우므로, 거의 상관관계가 없다.
Satis1 – Satis2 (0.1): 약한 양의 상관관계를 가지고 있다.
Age를 공변량(covariate)으로 통제한 뒤,
Satis1과 Satis2의 순수한 상관관계를 측정한다.
Satis.partial_corr(x='Satis1', y='Satis2', covar='Age').round(3)
CI95%는 상관계수 r에 대한 95% 신뢰구간이다.
즉, 실제 상관계수가 -0.36 ~ 0.54 사이에 있을 가능성이 95%라는 의미이다.
상관계수가 음수와 양수일 가능성을 모두 포함하는 넓은 범위는
상관관계가 약하다는 것을 의미한다.
p–값은 0.6(60%)이므로, 두 변수 사이의 상관관계는
유의하지 않다고 결론지을 수 있다.
결론적으로, 나이가 많을수록 제품의 기능과
디자인에 대한 만족도가 모두 증가하는 경향이 있다.
앞서 나이가 중요한 요인으로 확인되었으므로,
이번에는 나이를 30세 이하와 30세 초과로 나누어 산점도를 그려보았다.
Satis.loc[Satis.Age < 30,"AgeGroup"] = "Under30"
Satis.loc[Satis.Age >= 30,"AgeGroup"] = "Over30"
sns.jointplot(x = 'Satis1', y = 'Satis2',
data = Satis, hue = "AgeGroup")
# hue: 집단 변수(색을 구분하는 변수)
두 변수로 구분된 산점도가 전혀 겹치지 않고,
비선형적인 분포를 보이므로,
이들은 서로 연관성이 없다고 판단할 수 있다.
연령대별에 대한 상관계수를 출력해본다.
SatisUnder30 = Satis.loc[Satis.AgeGroup == "Under30",]
SatisOver30 = Satis.loc[Satis.AgeGroup =="Over30",]
from scipy.stats import pearsonr
print(pearsonr(SatisUnder30.Satis1, SatisUnder30.Satis2))
print(pearsonr(SatisOver30.Satis1, SatisOver30.Satis2))
상관계수의 값은 모두 낮고, 유의수준보다 p–값이 더 크므로,
두 변수 사이의 상관관계는 유의하지 않다고 결론지을 수 있다.
신뢰도 분석
측정 도구가 일관되게 측정하고 있는지를 평가하는 과정.

분산을 기반으로 두 변수 간의 관계 강도를 나타낸다.

식은 다음과 같이 분리된 형태로 표현된다.

오차 e와 진정한 값 t가 독립적이라고 가정하면 Cov( e, t ) = 0이다.

위 식을 대입한 뒤, 정리한다.

따라서, 신뢰도는 참점수 t와 관측점수 X의
분산비(ratio of variance)로 해석할 수 있다.

크론바흐의 알파
(Cronbach's alpha)

여러 문항이 동일한 개념을 얼마나 잘 측정하는지를 나타낸다.
위 계수는 0 ~ 1 사이의 값을 가지며,
값이 클수록 측정 도구의 신뢰도가 높다는 것을 의미한다.
사례
알파 계수 사용하여, 기업 구성원의 의식을 알아보기
import os
import pandas as pd
# 상대 경로 설정
file_path = os.path.join('data', 'Ability.csv')
# CSV 파일 읽기
Ability = pd.read_csv(file_path)
# 데이터 확인
Ability.head(10)

상사의 업무수행능력에 대한 신뢰도를 분석한다.
Ability[["Q01", "Q02", "Q03"]].corr()
import pingouin as pg
pg.cronbach_alpha(data = Ability[["Q01", "Q02", "Q03"]])
알파 계수의 값이 0.735로서 내적일관성 신뢰도가 높다는 것을 알 수 있다.
상사와의 공적/사적 긴밀함에 대한 신뢰도 분석하기.
Ability[["Q04", "Q05", "Q06", "Q07"]].corr()
pg.cronbach_alpha(data = Ability[["Q04", "Q05", "Q06", "Q07"]])
알파 계수의 값이 –0.222로 계산되었으며,
이 값은 신뢰도가 음수라는 것을 나타낸다.
일반적으로 알파가 음수값을 가질 경우,
문항들이 서로 일관성이 없음을 의미한다.
이는 측정 도구가 잘못 설계되었거나,
각 문항이 서로 다른 개념을 측정하고 있음을 나타낼 수 있다.
특히 문항 Q07이 나머지 문항들의 점수와
음의 상관을 가진다는 것을 알 수 있다.
이 신뢰구간은 크론바흐의 알파 값의 신뢰성을 보여준다.
신뢰구간의 하한이 –0.386이고 상한이 –0.073인 것으로,
신뢰구간 내에 음수가 포함되어 있다.
이는 크론바흐의 알파가 신뢰할 수 없는 상태임을 더욱 확증한다.
이 결과를 바탕으로 측정 도구의 문항을 재검토하거나
수정하는 것이 필요할 것으로 보인다.
Q07 문항의 값을 6에서 빼는 방식으로 역전환을 시도한다.
Ability["Q07_R"] = 6 - Ability.Q07
Ability[["Q04", "Q05", "Q06", "Q07"]].corr()
긍정적인 답변을 가진 경우,
다른 문항들과 반대되는 경향을 보여주기 때문이다.
pg.cronbach_alpha(data = Ability[["Q04", "Q05", "Q06", "Q07_R"]])
알파 계수의 값이 0.587로서 비교적 만족스럽고,
각 문항들과 다음 문항들의 점수와의 상관계수도
모두 양의 부호를 가진다는 것을 알 수 있다.
업무추진의 독자성에 대한 신뢰도 분석하기.
Ability[["Q08", "Q09", "Q10"]].corr()
pg.cronbach_alpha(data = Ability[["Q08", "Q09", "Q10"]])
알파 계수의 값이 0.251로 매우 낮게 나타나고 있다.
따라서, 이들 문항이 하나의 동질적인 개념을 측정한다는 것을 신뢰할 수 없으며
세 문항의 합점수를 사용하는 것은 문제가 된다는 것을 알 수 있다.
사용자 정의 함수를 이용하여,
표준화 크론바흐 알파의 계산식을 구현하였다.
import numpy as np
def CronbachAlpha(df):
df_corr = df.corr()
N = df.shape[1]
rs = np.array([])
for i,col in enumerate(df_corr.columns):
sum_ = df_corr[col][i+1:].values
rs = np.append(sum_, rs)
mean_r = np.mean(rs)
cronbach_alpha = (N * mean_r) / (1 + (N-1) * mean_r)
return cronbach_alpha
CronbachAlpha(Ability[["Q01", "Q02", "Q03"]])
일반적으로 크론바흐의 알파가 0.7 이상이면
문항들 간의 일관성이 적절하다고 평가된다.
CronbachAlpha(Ability[["Q04", "Q05", "Q06", "Q07"]])
음수가 나온 경우, 문항들 간에 부정적인 상관관계가 있을 가능성이 높으며,
문항들이 제대로 된 일관성을 가지지 못하고 있음을 나타낸다.
CronbachAlpha(Ability[["Q08", "Q09", "Q10"]])
이 값은 상대적으로 낮은 문항들 간의 상관성을 나타낼 수 있으며,
이는 문항들이 일관성이 부족하다는 것을 의미한다.
결과적으로 의미있는 신뢰도를 가진 문항은 Q01 ~ Q03 사이이다.
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)
'2024 - 2학기 > 데이터분석심화' 카테고리의 다른 글
| 제 6 장 두 모집단에 대한 비교 (10) | 2024.09.18 |
|---|