Reporting Date: September. 15, 2024
학습 플렛폼 데이스쿨(DACON)에서 초급 프로젝트 중 하나인
타이타닉호 침몰 사건의 생존자를 예측하는 프로젝트에 대해 다루고자 한다.
목차 3. 모델링 기초
4. EDA & 모델링 (1)
5. EDA & 모델링 (2)
6. 모델링
1 . 자 료 의 입 력
kaggle ⇨ Titanic - Machine Learning from Disaster ⇨ Data 카테고리
⇨ 3 개의 데이터셋 다운받기
## 다운받은 모든 파일은 현재 작업 디렉토리로 옮긴다.
import os
os.getcwd() # 현재 작업 디렉토리 출력
## 나의 현재 작업 디렉토리: C:\Users\jkl12\personal activity
## C:\Users\jkl12\Downloads\train.csv ⇨ C:\Users\jkl12\personal activity\train.csv
## 이를 통해 현재 작업 디렉토리에서 상대경로를 사용할 수 있다.
import pandas as pd
# 현재 작업 디렉토리에서 상대경로 설정
file_path = 'train.csv'
# CSV 파일을 DataFrame으로 로드
train = pd.read_csv(file_path)
train
# 현재 작업 디렉토리에서 상대경로 설정
file_path = 'test.csv'
# CSV 파일을 DataFrame으로 로드
test = pd.read_csv(file_path)
test
# 현재 작업 디렉토리에서 상대경로 설정
file_path = 'gender_submission.csv'
# CSV 파일을 DataFrame으로 로드
gender_submission = pd.read_csv(file_path)
gender_submission
2 . 데 이 터 확 인
데이터프레임의 열(컬럼) 이름 출력하기.
train.columns
| PassengerId: | 승객 고유 ID | Survived: | 생존 여부 (0 = 사망, 1 = 생존) |
| Pclass: | 승객 좌석 등급 (1, 2, 3등석) |
Name: | 승객 이름 |
| Sex: | 승객 성별 | Age: | 승객 나이 |
| SibSp: | 함께 탑승한 형제/배우자 수 |
Parch: | 함께 탑승한 부모/자녀 수 |
| Ticket: | 티켓 번호 | Fare: | 티켓 요금 |
| Cabin: | 객실 번호 | Embarked: | 승선한 항구 (C = Cherbourg, Q = Queenstown, S = Southampton) |
train 데이터프레임에 대한 요약 정보를 출력하기.
train.info()
train 데이터프레임의 기술 통계 요약 출력하기.
train.describe()
sample_submission.csv 파일 만들기.
# 'Survived' 열의 값을 모두 0으로 변경.
gender_submission['Survived'] = 0
# 변경된 데이터를 sample_submission.csv로 저장.
gender_submission.to_csv('sample_submission.csv', index = False)
print("sample_submission.csv 파일이 성공적으로 저장되었습니다.")
랜덤으로 생존 여부 생성하기.
import pandas as pd
import numpy as np
gender_submission = pd.read_csv('gender_submission.csv')
# 'Survived' 열을 가져오기.
survived_column = gender_submission['Survived']
# 난수 생성기 시드 설정하기.
np.random.seed(0)
# 'Survived' 열과 같은 길이의 난수 배열 생성.
survived = np.random.randint(0, 2, size=len(survived_column))
print(survived)
sample_submission.csv 파일 확인하기.
sample_submission['Survived'] = 0
sample_submission
submission 파일에 값 채우기.
sample_submission = pd.read_csv('sample_submission.csv')
sample_submission['Survived'] = survived
sample_submission
3 . 모 델 링 기 초
기초적인 모델링 작업부터 시작한다.
import pandas as pd
raw_data_train = pd.read_csv('train.csv')
raw_data_test = pd.read_csv('test.csv')
raw_data_submission = pd.read_csv('gender_submission.csv')
원본 데이터 복사하기.
train = raw_data_train.copy()
test = raw_data_test.copy()
submission = raw_data_submission.copy()
결측치를 다른 값으로 대체하기.
mean_age = train['Age'].mean()
mean_fare = train['Fare'].mean()
train['Age'] = train['Age'].fillna(mean_fare)
train['Fare'] = train['Fare'].fillna(mean_fare)
test['Age'] = test['Age'].fillna(mean_age)
test['Fare'] = test['Fare'].fillna(mean_fare)
머신러닝 모델을 학습시키기 위한,
데이터 전처리 및 데이터 분할을 수행하기.
train_x = train.drop(columns='Survived') # 독립 변수 X: 'Survived' 열을 제외한 나머지 열
train_y = train['Survived'] # 종속 변수 y: 'Survived' 열
# sklearn의 train_test_split 함수를 사용하여 데이터를 훈련, 검증 세트로 나누기
from sklearn.model_selection import train_test_split
# 데이터셋을 훈련, 검증 세트로 분할
# test_size = 0.2: 전체 데이터의 20%를 검증 세트로 사용
# random_state = 0: 분할을 재현 가능하게 하기 위한 시드 값
train_x, val_x, train_y, val_y = train_test_split(
train_x, train_y, test_size=0.2, random_state=0)
로지스틱 회귀(Logistic Regression) 모델을 정의하고 학습시키기.
import statsmodels.api as sm
train_dataset = pd.concat([train_x, train_y], axis=1)
formula = """
Survived ~ Age + SibSp + Parch + Fare
"""
model = sm.Logit.from_formula(formula, data=train_dataset)
result = model.fit()
수치형 변수들에 대한 기술 통계량(descriptive statistics) 출력하기. (4가지 방식)
print(result.summary())
print(result.summary2())
result.summary()
result.summary2()
학습된 로지스틱 회귀 모델을 사용하여 검증 데이터(val_x)에 대한
예측을 수행하고, 그 예측값을 이진 분류 형태로 변환하기.
# 결과 모델을 사용해 val_x에 대한 예측값을 생성
y_pred = result.predict(val_x)
# 0.5 이상의 값: 1, 그 이하: 0으로 변환
y_pred = y_pred.apply(lambda x: 1 if x >= 0.5 else 0)
혼동 행렬(confusion matrix)을 계산하여 분류 모델의 성능을 평가하기.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(val_y, y_pred))
classification_report를 사용하여, 분류 모델의 성능을 자세히 평가하기.
from sklearn.metrics import classification_report
print(classification_report(val_y, y_pred))
test 데이터에 대한 생존 여부 예측 및 결과 출력하기.
y_pred = result.predict(test)
y_pred = y_pred.apply(lambda x: 1 if x >= 0.5 else 0)
# 예측된 결과를 submission 데이터의 'Survived' 열에 저장
submission['Survived'] = y_pred
submission.head(15)
4 . E D A & 모 델 링 ( 1 )
본격적인 모델링 작업을 실시한다.
import pandas as pd
raw_data_train = pd.read_csv('train.csv')
raw_data_test = pd.read_csv('test.csv')
raw_data_submission = pd.read_csv('gender_submission.csv')
데이터의 분포 확인하기.
# 종속변수의 데이터 시각화
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(5,5))
sns.countplot(x=raw_data_train['Survived'])
plt.show()
# 독립변수의 시각화(범주형 변수)
columns = ['Pclass', 'Sex', 'Embarked']
for col_name in columns:
fig, ax = plt.subplots(ncols = 2, figsize = (10,5))
sns.countplot(x = raw_data_train[col_name],
palette = 'Set2',
ax = ax[0]).set(title = col_name + ' count plot')
sns.barplot(data=raw_data_train,
x = col_name,
y = "Survived",
palette = 'Set2',
ax = ax[1]).set(title = col_name + ' bar chart')
plt.show()


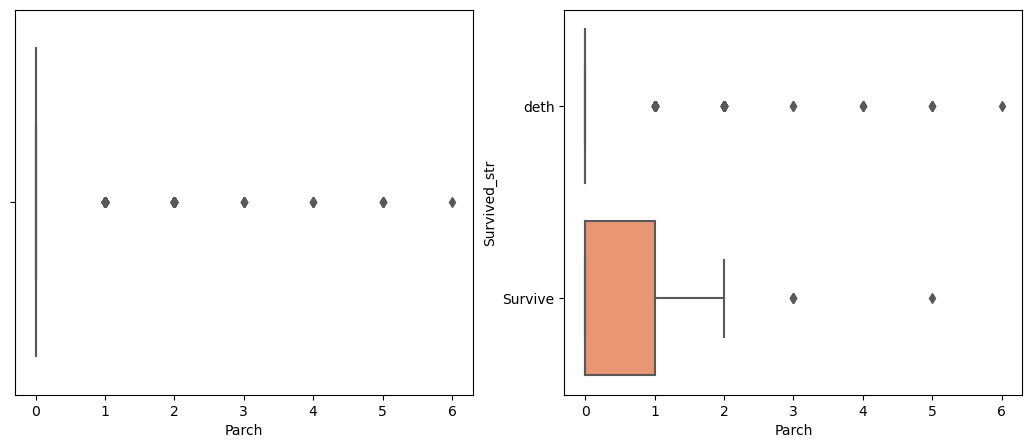
# 독립변수의 시각화(수치형 변수)
raw_data_train['Survived_str'] = raw_data_train['Survived'].apply(
lambda x: 'deth' if x == 0 else 'Survive')
columns = ['Age', 'SibSp', 'Parch', 'Fare']
for col_name in columns:
fig, ax = plt.subplots(ncols = 2, figsize = (13,5))
sns.boxplot(x = raw_data_train[col_name],
ax=ax[0],
palette = 'Set2')
sns.boxplot(data = raw_data_train,
x = col_name,
y = "Survived_str",
ax = ax[1],
palette = 'Set2')
plt.show()


결측치를 다른 값으로 대체하기.
# 데이터프레임 복사
train = raw_data_train.copy()
test = raw_data_test.copy()
submission = raw_data_submission.copy()
# 'Age'와 'Fare'의 평균값 계산
mean_age = train['Age'].mean()
mean_fare = train['Fare'].mean()
# 'Age', 'Fare' feature의 Null 값을 각 feature의 평균(mean)값으로 대체
train['Age'] = train['Age'].fillna(mean_age)
test['Age'] = test['Age'].fillna(mean_age)
train['Fare'] = train['Fare'].fillna(mean_fare)
test['Fare'] = test['Fare'].fillna(mean_fare)
수치형 독립 변수의 이상치 제거하기.
train = train[train['Parch'] <= 5]
train = train[train['Fare'] <= 300]
로지스틱 회귀 모델을 정의하고 학습시키기.
# 'Survived' 컬럼 제외 / 입력, 타겟 데이터 분리
train_x = train.drop(columns='Survived')
train_y = train['Survived']
from sklearn.model_selection import train_test_split
# 학습, 검증 데이터 분리
train_x, val_x, train_y, val_y = train_test_split(
train_x, train_y, test_size = 0.2, random_state = 0)
import statsmodels.api as sm
# 로지스틱 회귀모델을 위한 데이터셋 생성
train_dataset = train_x.copy()
train_dataset['Survived'] = train_y
# 로지스틱 회귀 모델을 위한 공식 (Survived를 종속 변수로 설정)
formula = """
Survived ~ C(Pclass) + C(Sex) + scale(Age)
+ scale(SibSp) + scale(Parch) + scale(Fare) + C(Embarked)
"""
# 모델 정의 및 학습
model = sm.Logit.from_formula(formula, data = train_dataset)
result = model.fit() # 모델 학습
print(result.summary())
실행된 로지스틱 회귀 모델의 결과 확인하기.
# 검증 데이터로 예측값 생성
# result 객체의 predict() 메서드로 val_x에 대한 예측 수행
y_pred = result.predict(val_x)
y_pred = y_pred.apply(lambda x: 1 if x >= 0.5 else 0)
from sklearn.metrics import confusion_matrix
# 실제 값(val_y)과 예측 값(y_pred) 비교하여 혼동 행렬 출력
print(confusion_matrix(val_y, y_pred))
from sklearn.metrics import classification_report
# 분류 성능 지표(정확도, 정밀도, 재현율 등) 출력
print(classification_report(val_y, y_pred))
예측값을 Submission 파일에 저장하기.
y_pred = result.predict(test)
y_pred = y_pred.apply(lambda x: 1 if x >= 0.5 else 0)
submission['Survived'] = y_pred
submission.head(15)
5 . E D A & 모 델 링 ( 2 )
가장 오류가 많이 발생한 모델링 파트이다.
이 파트에서 가장 중요한 것은 알맞은 데이터 타입의 유지이다.
import pandas as pd
raw_data_train = pd.read_csv('train.csv')
raw_data_test = pd.read_csv('test.csv')
raw_data_submission = pd.read_csv('sample_submission.csv')
원본 데이터를 복사한다.
# 데이터프레임 복사
train = raw_data_train.copy()
test = raw_data_test.copy()
submission = raw_data_submission.copy()
# 사용할 컬럼 리스트
columns = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
# 'Survived' 열을 포함하여 train 데이터에서 필요한 컬럼 선택
train = train[columns + ['Survived']]
# test 데이터에서는 'Survived'가 없으므로 선택한 columns만 사용
test = test[columns]
Age, Fare의 데이터 타입이 정수형이 안 되도록 하기.
# 결측값 처리
mean_age = train['Age'].mean()
mean_fare = train['Fare'].mean()
# 데이터 타입을 실수형으로 유지
train['Age'] = train['Age'].fillna(mean_age).astype(float)
test['Age'] = test['Age'].fillna(mean_age).astype(float)
train['Fare'] = train['Fare'].fillna(mean_fare).astype(float)
test['Fare'] = test['Fare'].fillna(mean_fare).astype(float)
# 이상치 제거
train = train[train['Parch'] <= 5]
train = train[train['Fare'] <= 300]
# 데이터 샘플 확인
print("Train Data Sample:")
print(train.head())
print("\nTest Data Sample:")
print(test.head())
Embarked_Q, Embarked_S의 데이터 타입이 문자형이 안 되도록 하기.
# 'Sex' 컬럼을 숫자로 변환 ('male' ⇨ 1, 'female' ⇨ 0)
train['Sex'] = train['Sex'].apply(lambda x: 1 if x == 'male' else 0)
test['Sex'] = test['Sex'].apply(lambda x: 1 if x == 'male' else 0)
# 'Embarked' 컬럼에 대해 더미 변수를 생성하고 첫 번째 카테고리를 드롭
train = pd.get_dummies(train, columns=['Embarked'], drop_first=True)
test = pd.get_dummies(test, columns=['Embarked'], drop_first=True)
# train 데이터의 Embarked_Q와 Embarked_S를 int로 변환
train[['Embarked_Q', 'Embarked_S']] = train[['Embarked_Q', 'Embarked_S']].astype(int)
# test 데이터의 Embarked_Q와 Embarked_S를 int로 변환
test[['Embarked_Q', 'Embarked_S']] = test[['Embarked_Q', 'Embarked_S']].astype(int)
test
알맞은 데이터 타입으로 유지되는지 확인하기.
print(train.dtypes)
print(test.dtypes)
독립변수와 종속변수로 분할한 뒤, 학습용 데이터(train_x)를 출력한다.
# 입력 변수와 타겟 변수 정의
# 'Survived'를 제외한 나머지 컬럼을 입력 변수로 설정
train_x = train.drop(columns='Survived')
# 'Survived' 컬럼을 타겟 변수로 설정
train_y = train['Survived']
from sklearn.model_selection import train_test_split
# 학습 데이터와 검증 데이터를 80:20 비율로 분리
train_x, val_x, train_y, val_y = train_test_split(
train_x, train_y, test_size=0.2, random_state=0)
train_x
데이터 불균형 해소를 위해,
소수 클래스의 샘플을 합성하여 데이터를 증강하기.
# SMOTE를 사용하려면
# 먼저 imbalanced-learn 패키지에서 SMOTE 클래스를 임포트해야 한다.
# pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
# SMOTE 객체 생성
smote = SMOTE(random_state=0)
# SMOTE를 사용하여 데이터의 클래스 불균형 보정
X_resampled, y_resampled = smote.fit_resample(train_x, list(train_y))
# y_resampled을 'Survived' 컬럼으로 추가하여 train_dataset을 생성
X_resampled['Survived'] = y_resampled
train_dataset = X_resampled
# 결과 확인
print("Resampled X shape:", X_resampled.shape)
print("Resampled y length:", len(y_resampled))
의사결정 트리(Decision Tree) 모델을 사용하여
주어진 학습용 데이터에 대한 패턴 학습하기.
# 모델링 학습
from sklearn.tree import DecisionTreeClassifier
# 모델 정의
model = DecisionTreeClassifier(max_depth=6, random_state=0)
# 모델 학습
model.fit(train_dataset.drop(columns='Survived'), train_dataset['Survived'])
의사결정 트리 모델에 대한 검증 데이터(val_x)의 예측 결과를 평가하기.
# 예측
y_pred = model.predict(val_x)
# 혼동 행렬 출력
from sklearn.metrics import confusion_matrix, classification_report
print("Confusion Matrix:")
print(confusion_matrix(val_y, y_pred))
# 분류 리포트 출력
print(classification_report(val_y, y_pred))
val_x
예측값을 Submission 파일에 저장하기.
# 예측
y_pred = model.predict(test)
submission['Survived'] = y_pred
submission['Survived'] = submission['Survived'].astype(int)
submission.head(15)
6 . 모 델 링
지금까지의 과정을 참고하여, 최종적인 모델링 작업을 진행한다.
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
전처리 하기.
import pandas as pd
from imblearn.over_sampling import SMOTE
# 사용할 컬럼 정의
columns = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
# train과 test 데이터프레임에서 사용할 컬럼 정의
train = train[columns + ['Survived']] # train 데이터는 'Survived' 컬럼도 포함
test = test[columns] # test 데이터는 독립 변수만 사용
# Null 처리 - 'Age'와 'Fare' 컬럼의 결측치를 각 값의 평균으로 대체
train['Age'] = train['Age'].fillna(train['Age'].mean())
test['Age'] = test['Age'].fillna(test['Age'].mean())
train['Fare'] = train['Fare'].fillna(train['Fare'].mean())
test['Fare'] = test['Fare'].fillna(test['Fare'].mean())
# 이상치 제거 - 'Parch': 5 이하 and 'Fare': 300 이하인 데이터만 남김
train = train[(train['Parch'] <= 5) & (train['Fare'] <= 300)]
# 'Sex' 컬럼에 apply 함수 사용하여 female: 0, 아니면: 1로 변환
train['Sex'] = train['Sex'].apply(lambda x: 0 if x == 'female' else 1)
test['Sex'] = test['Sex'].apply(lambda x: 0 if x == 'female' else 1)
# 'Embarked' 컬럼에 원-핫 인코딩 적용
train = pd.get_dummies(train, columns=['Embarked'], drop_first=True)
test = pd.get_dummies(test, columns=['Embarked'], drop_first=True)
# train 데이터의 Embarked_Q와 Embarked_S를 int로 변환
train[['Embarked_Q', 'Embarked_S']] = train[['Embarked_Q', 'Embarked_S']].astype('uint8')
# test 데이터의 Embarked_Q와 Embarked_S를 int로 변환
train[['Embarked_Q', 'Embarked_S']] = train[['Embarked_Q', 'Embarked_S']].astype('uint8')
# 독립변수(train_x)와 종속변수(train_y)로 나누기
train_x = train.drop('Survived', axis=1)
train_y = train['Survived']
# 데이터의 불균형을 해결하기 위해 SMOTE 알고리즘 적용
smote = SMOTE(random_state=0)
train_x_resampled, train_y_resampled = smote.fit_resample(train_x, train_y)
# 증강된 데이터를 다시 합하여 train_dataset 생성
train_dataset = pd.DataFrame(train_x_resampled)
train_dataset['Survived'] = train_y_resampled
print(train_dataset.head())
train_x
로지스틱 회귀(Logistic Regression) 모델을 정의하고 학습시키기.
import pandas as pd
import statsmodels.api as sm
from sklearn.metrics import classification_report, confusion_matrix
# 로지스틱 회귀식 정의
formula = """
Survived ~ C(Pclass)+ C(Sex) + scale(Age) + scale(SibSp)
+ scale(Parch) + scale(Fare) + C(Embarked_Q) + C(Embarked_S)
"""
# 모델 학습
model = sm.Logit.from_formula(formula, data=train_dataset)
result = model.fit()
# 예측
y_pred = result.predict(train_x) # train_x에 대한 예측값 계산
y_pred = (y_pred >= 0.5).astype(int) # 0.5 이상일 때 1로 변환 (이진 분류)
# 혼동 행렬 및 분류 보고서 출력
print(confusion_matrix(train_y, y_pred))
print(classification_report(train_y, y_pred))
의사결정 트리(Decision Tree) 모델을 사용하여
주어진 학습용 데이터에 대한 패턴 학습하기.
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 기존 train_x, train_y를 이용하여 train/validation 데이터 분할
train_x, val_x, train_y, val_y = train_test_split(
train_x, train_y, test_size = 0.2, random_state = 0)
# DecisionTreeClassifier 모델 생성
model = DecisionTreeClassifier(
max_depth = 6, random_state = 0)
# 모델 학습
model.fit(train_x, train_y)
# 검증 데이터(val_x)에 대한 예측
y_pred = model.predict(val_x)
# 혼동 행렬 및 분류 보고서 출력
print(confusion_matrix(val_y, y_pred))
print(classification_report(val_y, y_pred))
랜덤 포레스트(RandomForest) 분류모델을 사용하여,
타이타닉 데이터셋의 생존자를 예측하기.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 범주형 데이터 수치형으로 변환
def preprocess_data(df):
return pd.get_dummies(df, drop_first=True)
# 학습 데이터 전처리
X_train = preprocess_data(train.drop(columns='Survived'))
y_train = train['Survived']
# 검증 데이터 전처리
X_val = preprocess_data(val_x)
# 학습, 검증 데이터의 열을 동일하게 맞추기
X_val = X_val.reindex(columns=X_train.columns, fill_value=0)
# RandomForestClassifier 모델 생성
model = RandomForestClassifier(n_estimators=200, max_depth=5, random_state=0)
# 모델 학습
model.fit(X_train, y_train)
# 검증 데이터(val_x)에 대한 예측
y_pred = model.predict(X_val)
# 혼동 행렬 및 분류 보고서 출력
print(confusion_matrix(val_y, y_pred))
print(classification_report(val_y, y_pred))
XGBoost 모델 사용하여 모델을 학습하고,
검증 데이터에 대한 예측 결과를 출력하기.
# 아래 명령을 실행하면 xgboost 라이브러리가 설치된다.
# pip install xgboost
import pandas as pd
from xgboost import XGBClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 데이터 전처리 함수 정의
def preprocess_data(df):
# 범주형 변수 수치형으로 변환
return pd.get_dummies(df, drop_first = True)
# 학습 데이터 전처리
X_train = preprocess_data(train.drop(columns = 'Survived'))
y_train = train['Survived']
# 검증 데이터 전처리
X_val = preprocess_data(val_x)
# 학습, 검증 데이터의 열을 동일하게 맞추기
X_val = X_val.reindex(columns = X_train.columns, fill_value = 0)
# XGBClassifier 모델 생성
model = XGBClassifier(
n_estimators = 200, learning_rate = 0.01,
max_depth = 5, random_state = 0)
# 모델 학습
model.fit(X_train, y_train)
# 검증 데이터(val_x)에 대한 예측
y_pred = model.predict(X_val)
# 혼동 행렬 및 분류 보고서 출력
print(confusion_matrix(val_y, y_pred))
print(classification_report(val_y, y_pred))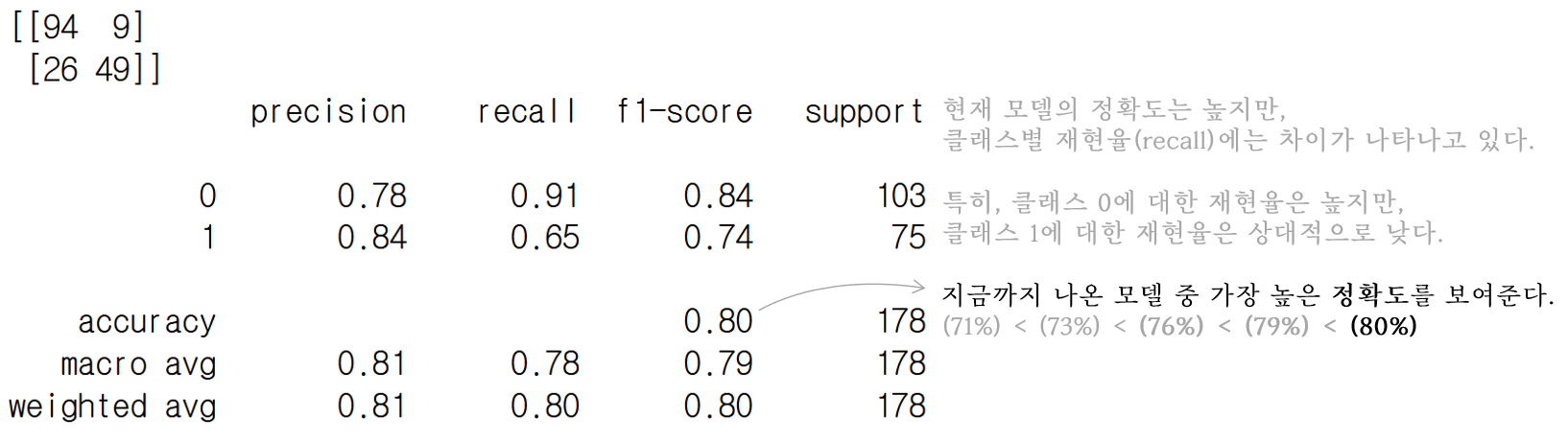
최종적으로, XGBClassifier 모델을 사용하여 학습을 진행하였다.
from xgboost import XGBClassifier
# XGBClassifier 모델 생성
my_model = XGBClassifier(
n_estimators = 200, learning_rate = 0.01,
max_depth = 5, random_state = 0)
# 모델 학습
my_model.fit(train_dataset.drop(columns = 'Survived'),
train_dataset['Survived'])
# 예측
XGB_pred = my_model.predict(
train_dataset.drop(columns = 'Survived'))
# 제출 준비
y_pred = my_model.predict(test)
submission['Survived'] = y_pred
submission.head(15)
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)