15장: 범주형 자료분석
Reporting Date: August. 12, 2024
관측치들이 몇 개의 범주로 분류되고, 각 범주의 도수로 자료가 주어지는
범주형 자료에 대해 다루고자 한다.
목차2. 적합도 검정 (Goodness–of–Fit Test)
2-1. 피어슨의 χ ² 적합도 검정
2-2. χ ² 분포의 특징
1 . 자 료 의 입 력
## 교재 출처 최하단에 표시 ##
# 예제 9: 파이썬을 이용하여 예제 4의 자료를 분석하라.
# 예제 4: 예제 1에서 주어진 자료에 대한 귀무가설을 유의수준 α = 0.05로 검정하라.
#-----------------------------------------------------------------------
# 예제 1: (몇 개의 범주로 분류된 한 표본의 문제)
# 어떤 나무의 자가수정의 결과로 나올 수 있는 유전자의 형태는
# 세 종류로 분류된다고 한다.
# 이 세 종류를 각각 A, B, C라고 할 때
# 생물학에서의 한 이론에 의하면 비율이 1 : 2 : 1로 나타난다고 하자.
# 이를 입증하기 위하여 자가수정의 결과로 생겨난 나무 100그루를
# 유전자의 형태별로 분류하였다.
#-----------------------------------------------------------------------
import numpy as np
O = np.array([18, 55, 27])
Pr = np.array([0.25, 0.5, 0.25]) # 1 : 2 : 1
n = O.sum()
E = n * Pr
df = len(O) - 1
#______________________________________________________________________
# 예제 10: 파이썬을 이용하여 예제 5의 자료를 분석하라.
# 예제 5: 예제 2의 자료에서 두 식이요법 간에
# 차이가 있다고 할 수 있는지를 유의수준 α = 0.05로 검정하라.
#-----------------------------------------------------------------------
# 예제 2: (몇 개의 범주로 분류된 두 개의 독립인 표본의 문제)
# 두 가지 식이요법 A와 B의 효과를 비교하기 위해서
# 150명의 환자를 대상으로 조사를 실시하였다.
# 임의로 추출된 80명에게는 식이요법 A를 적용하고,
# 나머지 70명에게는 식이요법 B를 적용한 후
# 얼마간의 시간이 흐른 후에 각 환자의 건강상태에 따라
# 세 가지 범주로 분류하였다.
#-----------------------------------------------------------------------
import pandas as pd
import numpy as np
diet = np.array([[37, 24, 19], [17, 33, 20]])
column_names = ['Good', 'Normal', 'Bad']
row_names = ['diet_A', 'diet_B']
table = pd.DataFrame(diet, columns=column_names, index=row_names)
table
2 . 적 합 도 검 정 ( Goodness–of–Fit Test )
특정 데이터가 주어진 분포 모델에 얼마나 잘 맞는지를 검정하는 것.
예제 1

각 유전자 형태에 대응되는 모집단의 비율을 pA, pB, pC 라고 할 때
위에서 얻어진 자료로부터 생물학 이론이 제시하는 가설이 틀리는지 판단하기 위해서
다음과 같은 귀무가설을 검정하고자 한다:

2 - 1 . 피 어 슨 의 χ ² 적 합 도 검 정
예제1과 같이 자료가 몇 개의 범주에 대한 관측도수 형태로 주어지는 문제를 다룰 때 사용한다.
크기가 n인 표본을 k개의 범주로 분류할 때
각 범주의 관측도수를 n1, ⋯, nk 라고 하자.
그리고 각 범주에 대응되는 모집단의 비율을 p1, ⋯, pk 라고 하면
귀무가설들은 각 pi 들에 어떤 이론에서 제시하는 값 pi0 들을 대응하는 형태를 지닌다:

두 도수의 차이가 클 경우, 귀무가설을 기각하게 된다.
위 가설을 검정하기 위한 검정통계량은 다음과 같다:

위 검정통계량은 표본의 크기가 클 경우,
자유도가 (범주의 개수) – 1 = k – 1 인
(카이제곱) χ ² 분포를 따른다고 알려져 있다.
따라서, 유의수준 α 를 갖는 기각역은 다음과 같다:

2 - 2 . χ ² 분 포 의 특 징
(1) 독립인 표본으로부터 계산된 χ ² 통계량들을 더하면
그 합도 χ ² 분포를 따르며, 자유도는 각 자유도의 합과 같다:

(2) χ ² 통계량을 계산하는데 만약 모수의 추정치를 사용하였다면
통계량 분포의 자유도는 추정한 모수의 개수만큼 감소하게 된다:

3 . 동 질 성 검 정 ( Homogeneity Test )
독립인 두 그룹이 독립인 각 범주별로 동일한 반응형태를 보이는가를 검정하는 것.
예제 2
분할표( Contingency Table ):
표본의 관측치를 둘이나 그 이상의 특성에 따라 분류하여 도수로 나타내는 자료.

위 자료로부터 두 식이요법 간에 차이가 있는지를 알아보기 위해
다음의 귀무가설을 검정하게 된다:

위 가설을 검정하기 위한 검정통계량은 다음과 같다:
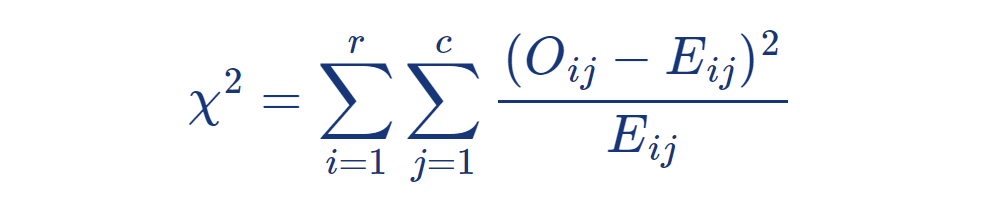
r 개의 모집단에서 독립적으로 추출한 표본을
c 개의 반응범주로 분류하는 일반적인 r × c 분할표로 확장하여 보자.
여기에서 달라지는 것은 행과 열의 수뿐이므로
각 칸에서의 추정기대도수는 (행의 합 × 열의 합)/(전체 합) 의 형태로 주어진다.
또한 χ ² 의 자유도는
각 r 개의 행이 독립인 모집단을 나타내고
각 행마다 c 개의 열(범주)이 있으므로
χ ² 의 성질 (i)에 따라 모수가 알려져 있다면 자유도는 r ( c – 1 ) 이 된다.
그러나 모수인 각 범주의 공통비율 p1, ···, pc 가 미지수이므로
이를 추정하면 χ ² 의 성질 (ii)에 의하여 자유도는 추정한 모수의 개수만큼 감소한다.
여기서 p1 + ··· + pc = 1 이라는 사실로부터 실제로 추정하는 모수의 개수는 c – 1 개이므로
검정통계량 χ ² 의 자유도는 다음과 같이 주어진다:
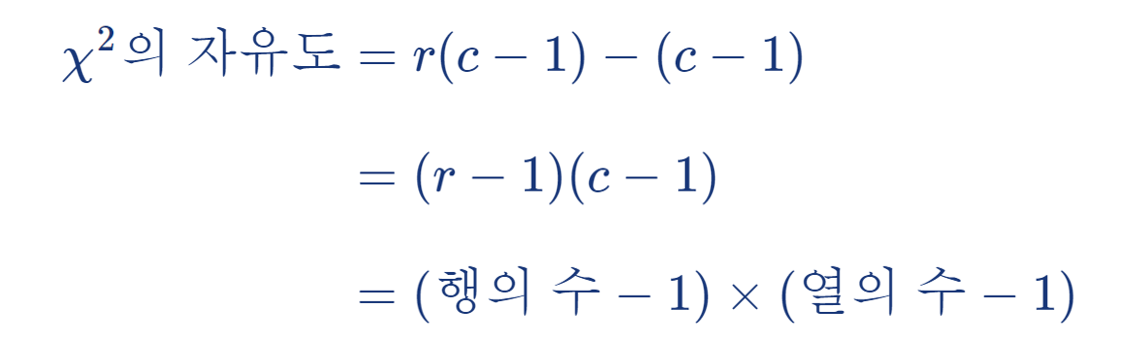
유의수준 α 를 갖는 기각역은 다음과 같다:

4 . 독 립 성 검 정 ( Independence Test )
두 가지 특성이 서로 독립인지를 검정하는 것.
예제 3

위 표는 예제 2 의 표와 동일한 모양을 하고 있지만
표본추출에 있어 근본적으로 다른 점을 가지고 있다.
예제 2 의 행의 합 (80, 70) 은 미리 정해진 값이고,
열의 합 (54, 57, 39) 은 임의표본추출의 결과로 미리 정해진 값이 아니다.
반면에 예제 3 의 경우에는 행과 열의 합 모두 표본추출 이전에 미리 정해지지 않는다.
그러므로, 예제 2 의 표를 행과 열 중 한쪽이 고정된 분할표라고 하고,
예제 3 의 표를 행과 열 중 어느 쪽의 합도 고정되지 않은 분할표라고 한다.
위 자료로부터 두 가지 특성이 서로 독립인지를 알아보기 위해
다음의 귀무가설을 검정하게 된다:

일반적인 r × c 분할표에서의 독립성 검정은
행과 열의 수만 다를 뿐 검정 방법은 동질성 검정과 동일하다.
자유도에 경우, 하나의 모집단이 rc 개의 칸으로 나뉘어 있으므로
원래라면 ( rc – 1 ) 자유도가 된다.
그러나, 실제로 추정하게 되는 모수의 개수가
열에서 ( c – 1 ) , 행에서 ( r – 1 )개 이므로 ( r – 1 ) + ( c – 1 ) 이 된다:

결론적으로 독립성 검정은 동질성 검정과
추정된 기대도수의 형태, 검정통계량, 자유도, 기각역이 모두 동일하다.
단지 검정하고자 하는 가설이 달라서 검정 결과에 대한 해석이 달라진다.
예제 9
from scipy import stats
chi2, p = stats.chisquare(O, E)
print("Chi-squared test for given probabilities",
"\n", "\n",
"Chi-Squared :", round(chi2, 4), "\n",
"df :", df, "\n",
"P-Value :", round(p, 4))
## 해석: P–값 0.2698을 얻는다.
## 이 값은 유의수준 0.05(5%), 0.1(10%)보다도 큰 값이므로
## 생물학의 이론이 제안한 모집단의 비율에 적합하다고 결론을 내릴 수 있다.
예제 10
from scipy import stats
chi22, p2, dof, expected = stats.chi2_contingency(diet)
print ("Pearson's Chi-squared test", "\n", "\n",
"Chi-Squared :", round(chi22, 4), "\n",
"df :", dof, "\n",
"P-Value :", round(p2, 4))
## 해석: P–값이 0.0164로 매우 작으므로
## 유의수준 0.025(2.5%)에서도 식이요법 A, B는
## 차이가 없다는 귀무가설을 기각할 수 있다.
글씨체 바꿔 주는 사이트 - Exotic Text
Symbols (wumbo.net)