Reporting Date: July. 11, 2024
5 장에서 다룬 표본공간의 근원사건들은 특성을 표현하는 형태로 다뤘다.
이제는 확률변수를 중심으로 실험의 수치적 결과에 대해 다루고자 한다.
1 . 확 률 변 수 ( Random Variable )
각각의 근원사건들에 실수값을 "대응시키는 함수"이며 X, Y, … 등으로 표시한다.
확률변수가 가질 수 있는 "값의 개수" 가 유한하거나
무한이라도 "셀 수 있는 경우" 에 이를 "이산확률변수" 라고 한다.
또한, 연속적인 구간에 속하는 모든 값을 다 가질 수 있는 "연속확률변수" 도 있다.
2 . 이 산 확 률 분 포 ( Discrete Probability Distribution )
확률변수가 갖는 값들과 그에 "대응하는 확률값" 을 나타내는 것으로,
나열된 표나 수식으로 표현되며, 보통은 "확률변수 X 의 분포" 라고 한다.
2 - 1 . 확 률 질 량 함 수 ( Probability Mass Function, PMF )
확률변수 X 가 k 개의 값 x₁, x₂, …, xk 를 가질 때,
그에 대응하는 확률을 f(x₁), f(x₂), …, f(xk) 라고 하면
X 의 확률분포는 다음과 같다:

f ( x ) 는 확률변수 X 가 값 x 를 갖게 되는 확률 P ( X = x ) 을 나타낸다:

이산확률변수 X 의 확률변수는 다음 조건을 만족해야 한다:

모든 확률은 0 이상 1 이하의 값을 가진다.
확률변수가 가질 수 있는 모든 값에 대한 확률의 합은 1 이다.
3 . 이 산 확 률 변 수 의 평 균과 표 준 편 차
3 - 1 . 기 댓 값 ( Expected Value )
E ( X ) 는 확률변수 X 의 "기댓값(평균)"
또는 X 가 갖는 확률분포의 "모평균" 이라고 한다.

3 - 2 . 모 분 산 ( Population Variance )
편차 ( 즉, 각 값이 기대값에서 얼마나 떨어져 있는지 ) 를 "제곱" 하고,
그 제곱된 값을 각 값이 발생할 확률로 "가중평균" 하는 것이다.
V a r ( X ) = ∑ ( 편차 ) ² × 확률:

모 분 산 의 간 편 식:

3 - 3 . 모 표 준 편 차 ( Population Standard Deviation )
모분산의 양의 제곱근으로 계산된다:

모표준편차 ( σ ) 의 단위는 확률변수 X와 "동일" 하다.
반면 모분산 ( σ² ) 의 단위는 의 단위를 "제곱" 한 것이므로,
퍼진정도를 측정하는데 적절하지 않다.
예를 들어, X 의 단위가 센티미터( cm )라면,
모분산 σ² 의 단위는 제곱센티미터( cm² )가 된다.
4 . 두 확 률 분 포 의 결 합 분 포
하나의 실험에서도 2 개 이상의 측면에 대한 관측이 가능하다.
이 경우 그 2 가지 특성 간의 관계 여부 및 그 관계 정도에 대해 분석할 수 있다.
4 - 1 . 결 합 확 률 분 포 ( Joint Probability Distribution )
2 개 이상의 확률변수가 동시에 특정한 값을 가질 확률을 나타내는 분포이다.
2 개의 확률변수가 이산일 경우,
X 가 취하는 값을 x₁, …, xm
Y 가 취하는 값을 y₁, …, yn 이라고 할 때
X 와 Y 의 결합확률분포는
모든 1 ≤ i ≤ m, 1 ≤ j ≤ n 에 대하여

위 식을 구하므로써 결정되며, 다음과 같이 표현할 수 있다:

4 - 2 . 주 변 확 률 분 포 ( Marginal Probability Distribution )
결합확률분포에서 한 확률변수를 "고정" 하고 다른 변수의 분포를 고려하는 분포이다.
이는 2 개 이상의 확률변수 중 하나에 대한 "단일 확률분포" 를 얻기 위해 사용한다:

각각의 주변확률을 이용해서 하나의 변수 때와 마찬가지로 구하면 된다:

5 . 공 분 산 과 상 관 계 수
5 - 1 . 공 분 산 ( Covariance )
두 확률변수 X 와 Y 가 함께 변하는 정도를 측정한다.

X, Y가 같은 방향으로 변화할 경우, (즉, 둘 다 증가하거나 둘 다 감소하는 경우)
( X − μX ), ( Y − μY ) 의 부호가 일치할 확률이 상대적으로 커진다.
따라서, 이에 대한 기댓값은 양수가 된다.
X, Y가 다른 방향으로 변화할 경우, (즉, 한 변수가 증가할 때 다른 변수는 감소하는 경우)
( X − μX ), ( Y − μY ) 가 서로 다른 부호를 갖게 될 확률이 상대적으로 커진다.
따라서 이에 대한 기댓값은 음수가 될 것이다.
X, Y 의 공분산은 아래와 같이 정의된다:

5 - 2 . 상 관 계 수 ( Correlation Coefficient )
두 확률변수 간의 선형 관계의 강도와 방향을 측정한다.
이것은 공분산을 표준화한 형태로, −1 과 1 사이의 값을 가진다.

상관계수의 성질:
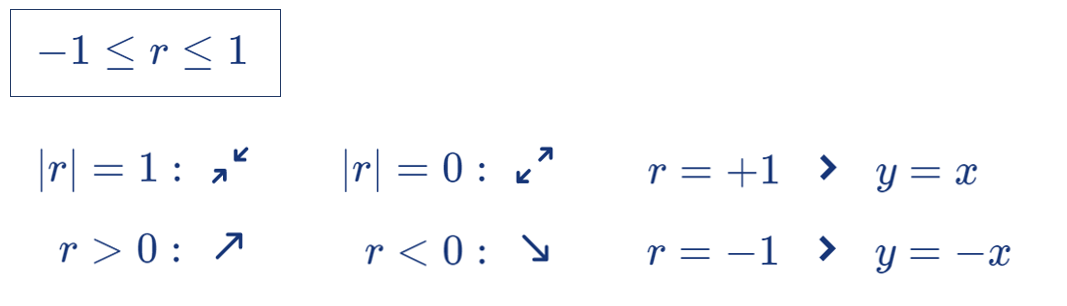
절댓값이 클수록 (1 또는 −1에 가까울수록) 점들은 기울기가 양수(또는 음수)인 직선에 가깝게 몰려 있다.
0보다 값이 클 경우, 점들이 좌하에서 우상방향으로 띠를 형성한다.
이때, 한 변수의 값이 크면 다른 변수의 값도 큰 경향을 가진다.
정확한 선형관계 Y = aX + b 가 성립할 때, 상관계수의 값은 −1 또는 1 이다.
X, Y 의 상관계수는 각 확률변수에 상수가 더해지거나 감해지는 것에 영향을 받지 않는다.
상수가 곱해진 경우, 그 부호에만 영향을 받는다.

6 . 두 확 률 변 수 의 독 립 성
2 개의 확률변수 X, Y 가 독립이 되기 위해서는
X, Y 가 취하는 모든 쌍의 값 ( xi, yi ) 에 대해 아래 식을 만족해야 한다.

두 확률변수 X, Y 가 서로 독립일 때,
아래의 식이 성립한다:


단, 공분산과 상관계수가 0 이라는 사실이
항상 두 변수가 독립이라는 것을 보장하지 않는다.
이는 두 변수 간에 선형 관계가 없음을 의미하지만, 비선형 관계가 존재할 수 있다.
두 확률변수가 독립일 경우,
공분산이 0 이 되므로 합과 차의 분산을 쉽게 계산할 수 있다.
분산과 공분산의 정의를 이용하면:

공분산 항을 제외하여 다음과 같이 나타낼 수 있다:

Symbols (wumbo.net)
참고용 블로그: 작은 숫자 특수문자 첨자 및 분수숫자 모음
'2024 - 1학기 > 데이터분석입문' 카테고리의 다른 글
| 8장: 정규분포 (2) | 2024.07.18 |
|---|---|
| 7장: 이항분포와 그에 관련된 분포들 (4) | 2024.07.15 |
| 5장: 확률 (0) | 2024.07.08 |
| 4장: 두 변수 자료의 요약 (0) | 2024.07.04 |
| 3장: 수치를 통한 연속형 자료의 요약 (2) | 2024.06.30 |