Reporting Date: July. 18, 2024
6 장에서 언급되었던, 연속적인 값을 가지는 연속확률분포들 중에서
대부분의 통계학 이론의 기본이 되는 정규분포에 대해 다루고자 한다.
1 . 자 료 의 입 력
## 교재 출처 최하단에 표시 ##
# 예제 7: 어느 대학교의 일반수학 중간고사 성적은
# 분포가 평균이 63 이고, 분산이 100 인 정규분포를 따른다고 가정한다. (p.232)
# (1) 50 점 이하의 학생은 몇 퍼센트나 되겠는가?
# (2) 상위 10 %의 학생에게 A 를 준다고 하면
# 몇 점 이상이 되어야 A 를 받을 수 있겠는가?
# ___________________________________________________________
# 예제 12: 정규확률그림을 그려라. (p.247)
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
data1 = np.array([4001, 3927, 3048, 4298, 4000, 3445,
4949, 3530, 3075, 4012, 3797, 3550,
4027, 3571, 3738, 5157, 3598, 4749,
4263, 3894, 4262, 4232, 3852, 4256,
3271, 4315, 3078, 3607, 3889, 3147,
3421, 3531, 3987, 4120, 4349, 4071,
3683, 3332, 3285, 3739, 3544, 4103,
3401, 3601, 3717, 4846, 5005, 3991,
2866, 3561, 4003, 4387, 3510, 2884,
3819, 3173, 3470, 3340, 3214, 3670,
3694])
# ___________________________________________________________
# 예제 13: 어느 숲속에서 49그루의 나무의 체적을 측정한 자료이다.
# 히스토그램을 그리고 적절한 변환을 하여 정규분포로 접근시켜 보아라. (p.249)
import numpy as np
import matplotlib.pyplot as plt
data2 = np.array([39.3, 14.8, 6.3, 0.9, 6.5,
3.5, 8.3, 10.0, 1.3, 7.1,
6.0, 17.1, 16.8, 0.7, 7,9,
2.7, 26.2, 24.3, 17.7, 3.2,
7.4, 6.6, 5.2, 8.3, 5.9,
3.5, 8.3, 44.8, 8.3, 13.4,
19.4, 19.0, 14.1, 1.9, 12.0,
19.7, 10.3, 3,4, 16.7, 4.3,
1.0, 7.6, 28.33, 26.2, 31.7,
8.7, 18.9, 3.4, 10.0])
2 . 연 속 확 률 분 포 ( Continuous Probability Distribution )
연속확률변수 X 가 가질 수 있는 값들의 분포를 나타낸다.
연속확률변수: 특정 범위 내에서 모든 실수 값을 가질 수 있는 변수.
2 - 1 . 확 률 밀 도 함 수 ( Probability Density Function, PDF )
연속확률변수 X 의 확률분포는 확률의 밀도를 나타내는
X 의 확률밀도함수에 의해 결정된다.
아래의 조건을 만족하는 함수 f ( x ) 를
X 의 확률밀도함수라고 한다.

예를 들어, [ 0, 1 ] 구간에 있는 실수 값은 무한히 많다.
이러한 경우, 특정한 하나의 값을 가질 확률은 무한히 작은 값이 되며,
이는 수학적으로 0 으로 표현된다.
범위 : 확률밀도함수 f ( x ) 의 값은 항상 0 이상이어야 한다.
이는, 어떤 사건의 확률이 음수일 수 없다는 것을 의미한다.
확률밀도함수는 이산확률분포의 확률함수와는 달리 확률을 나타내지 않는다.
그러므로, f ( x ) 가 1 보다 작아야 된다는 조건 은 필요가 없다.


위 조건으로부터 다음과 같은 결론을 내릴 수 있다:

3 . 정 규 분 포 ( Normal Distribution )
평균 μ 와 분산 σ ² 의해서 그 분포가 확정된다.
그 확률밀도함수 ( PDF ) 의 대략적인 특성은
다음과 같이 표현할 수 있다:

X 가 평균 μ 로부터 ± σ, ± 2σ, ± 3σ, ± 4σ 의 사이의 있을 확률은 다음과 같다.

이를 통해 ± 4σ 이상 떨어진 데이터는 매우 드문 현상임을 알 수 있다.
그러므로, 정규분포의 ± 4σ 이상의 영역은 실질적인 분석에서 종종 무시할 수 있다.
3 - 1 . 정 규 분 포 의 특 성

3 - 2 . 표 준 정 규 분 포 ( Standard Normal Distribution )
평균 ( μ ) 이 0 이고 표준편차 ( σ )가 1 인 특수한 정규분포.
확률변수 Z 가 N ( 0, 1 ) 이라고 할 때,
Z 는 0 을 중심으로 대칭인 분포를 갖게 되며,
이를 이용해 다음과 같이 나타낼 수 있다:

누적분포함수 ( CDF ) 는 특정 값 이하의 확률을 나타낸다.
- P ( Z ≤ b ) 는 Z 가 b 이하일 확률이고,
- 는 Z 가 a 이하일 확률이다.
따라서 a 에서 b 까지의 확률은 다음과 같다:

3 - 3 . 표 준 정 규 확 률 변 수 ( Standard Normal Random Variable )
표준정규분포 Z 에 관한 확률계산 방법을 일반 정규분포 X 의 확률계산에 적용할 수 있다.
일반 정규분포 X 를 표준정규분포 Z 로의 식변환을 통해
쉽게 계산할 수 있으며, 이를 표준화라고 한다.
확률변수 X 가 N ( μ, σ² ) 일 때
표준화된 확률변수 Z 는 정규분포 N ( 0, 1 ) 을 따른다.

예제 7의 ( 1 )
중간고사 성적을 확률변수 X 라고 하면
주어진 정보를 바탕으로 다음과 같이 표현할 수 있다:


from scipy.stats import norm
print(norm.cdf(x=50, loc=63, scale=10))
## 출력된 값 > 0.09680048458561036
## 해석: 50 점 이하의 학생의 비율은 0.0968 = 9.68% 이다.
예제 7의 ( 2 )
x 점 이상의 학생들에게 A 를 준다고 하면
x 는 다음을 만족해야 한다:

먼저, 표준정규분포표로부터
P [Z ≥ z] = 0.10 이 되는 z 값을 찾는다:
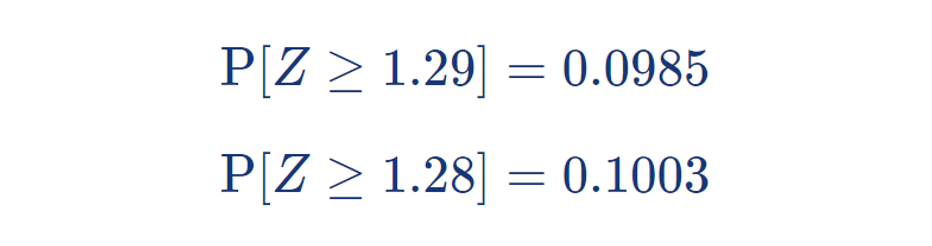
이 경우, 0.10 에 가까운 값을 주는 z = 1.28 을 고르면 된다:

from scipy.stats import norm
print(norm.ppf(q=0.9, loc=63, scale=10))
## 출력된 값 > 75.815515655446
## 해석: 상위 10 %의 학생에게 A 를 준다고 하면
## 75.8 점 이상의 점수를 받은 학생에게 주면 된다.
4 . 이 항 분 포 의 정 규 분 포 근 사
대규모 시행에서 이항 분포를 정규 분포로 근사하는 방법.
7장의 초기하 분포나, 포아송 분포 마찬가지로,
정규 분포로도 근사하여 계산할 수 있다.
이항 분포는 n 이 커짐에 따라 근사적으로 정규분포를 따르게 된다.
이때 정규분포의 평균과 분산은 이항분포의에서와 일치하여야 한다:

4 - 1. 연 속 성 수 정 ( Continuity Correction )
이항 분포의 이산적인 값을 연속적인 정규 분포의 구간에 맞추는 작업.
보통 ± ½ 를 가감하여 근삿값을 계산한다.
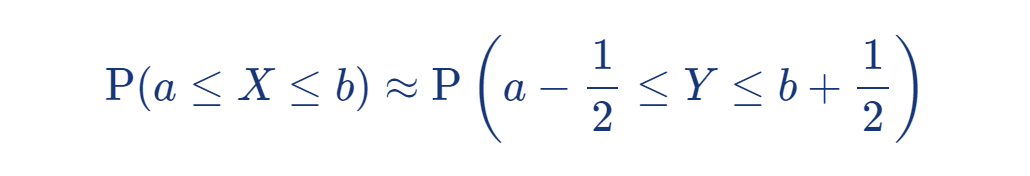
확률변수 X 가 이항분포, 즉 X ~ Bin ( n, p ) 이고,
np, nq ( =1 − p ) 가 모두 클 경우 ( 보통 10 이상 )
X 는 근사적으로 평균이 np, 표준편차가 √npq 인 정규분포를 따른다.

5 . 정 규 분 포 가 정 의 조 사
모집단의 분포가 정규 분포를 따른다는 가정을
조사하기 위해 사용할 수 있는 효과적인 그림.
- 정규점수그림 ( Normal Scores Plot ) 또는
- 정규확률그림 ( Normal Probability Plot ) 으로 불린다.
5 - 1 . 정규점수 ( Normal Scores )
표본 데이터와 표준 정규 분포 ( 평균 0, 표준편차 1 ) 를 비교하여
데이터의 정규성을 평가하는 데 사용된다.
정규성( Normality ) : 데이터가 정규 분포를 따르는지를 의미한다.
즉, 표준정규분포의 확률밀도함수 ( PDF ) 를
등확률 구간으로 나누어 주는 경곗값 ( z 값 ) 을 의미한다.
그림으로부터 분포의 형태를 알기 위해선
자료의 크기가 적어도 15 이상은 되어야 한다.
5 - 2 . 정규확률그림 그리는 순서
- 자료를 작은 것부터 크기순으로 나열한다.
- 각 자료에 해당하는 점수를 계산한다.
- i 번째 순서의 자료와 i 번째 순서의 정규점수를 하나의 쌍으로 2 차원 공간상에 나타낸다.
5 - 3 . 정규그림의 해석

5 - 3 . 정규확률그림을 이용한 정규성 판정
- 직선식일 경우, 정규분포의 가정이 타당하다고 볼 수 있다.
- (곡선 등) 직선식을 벗어날 경우, 가정이 의문시된다고 할 수 있다.
# 예제 12: 정규확률그림을 그려라. (p.247)
sm.qqplot(data1, line = "s")
# "s"는 "standardized"를 의미한다.
# 이 옵션은 플롯에 표준화된 선
# (평균 0, 표준편차 1의 정규 분포)에 맞추어 선을 그린다.
plt.title("Normal Q-Q plot")
## 해석: 데이터 포인트들이 직선에 가까우므로
## 데이터가 정규분포를 따를 가능성이 높다.
5 - 4 . 자 료 의 변 환
만약 추출된 표본이 정규확률그림 등에서 정규분포와 상당히 벗어난 것으로 판명되면,
자료의 변환을 통해 정규분포의 형태를 갖도록 시도해 볼 수 있다.
# 예제 13: 어느 숲속에서 49그루의 나무의 체적을 측정한 자료이다.
# 히스토그램을 그리고 적절한 변환을 하여 정규분포로 접근시켜 보아라. (p.249)
plt.hist(data2, bins=5, range=(0,50))
pit.xlabel('data2')
pit.ylabel('Density')
plt.title('Historam of data')
## 해석: 아래 히스토그램을 보면 자료의 분포가 왼쪽으로 편중되어 있으므로
## 정규분포가 아니라는 의심을 할 수 있다.
sm.qqplot(data2, line = "s")
plt.title("Normal Q-Q plot")
## 해석: 데이터 포인트들이 직선에서 크게 벗어나
## 데이터가 정규 분포를 따르지 않을 가능성이 있음을 확인할 수 있다.
이 경우, 큰 자룟값을 더 작게 만드는 과정을 수행한다:
# 원 자료를 제곱근(체적^(0.5))으로 변환한 결과
data3 = np.sqrt(data2)
sm.qqplot(data3, line = "s")
plt.title("Normal Q-Q plot")
# 원 자료를 네제곱근(체적^(0.25))으로 변환한 결과
data4 = np.power(data2, 0.25)
sm.qqplot(data4, line = "s")
plt.title("Normal Q-Q plot")
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)
참고용 블로그: 작은 숫자 특수문자 첨자 및 분수숫자 모음
교제: 통계학: 파이썬을 이용한 분석
'2024 - 1학기 > 데이터분석입문' 카테고리의 다른 글
| 10장: 통계적 추론 (4) | 2024.07.25 |
|---|---|
| 9장: 표집분포 (10) | 2024.07.21 |
| 7장: 이항분포와 그에 관련된 분포들 (4) | 2024.07.15 |
| 6장: 확률분포 (4) | 2024.07.11 |
| 5장: 확률 (0) | 2024.07.08 |