Reporting Date: July. 25, 2024
추출된 표본으로부터 모집단의 일반적인 특성을 추론해내는 것을
통계적 추론이라고 하며, 이는 표본의 크기가 클 때 더 정확하게 성립한다.
1 . 자 료 의 입 력
## 교재 출처 최하단에 표시 ##
# 예제 13: 예제 1 에 주어진 자료에 근거해서
# 중학교 1학년 남학생의 평균키에 대한 95% 신뢰구간을 구하라. (p.311)
import numpy as np
height = np.array([163, 161, 168 , 161, 157, 162, 153, 159, 164, 170,
152, 160, 157, 168, 150, 165, 156, 151, 162, 150,
156, 152, 161, 165, 168, 167, 165, 168, 159, 156])
#_____________________________________________________________________________
# 예제 14: 예제 8의 검정을 시행하고 그 결과를 비교하여라. (p.313)
# 예제 8: 앞의 예제 1에 주어진 중학생의 키 자료로부터
# 그 도시의 중학교 1학년 남학생의 평균키(m)가 다른 도시의 중학교 1학년
# 남학생의 평균키인 159 cm와 차이가 있다고 할 수 있는지 판단하라. (p.297)
#_____________________________________________________________________________
# 예제 15: 3 장의 예제 11 에 주어진 자료로부터
# 평균교통소음정도(μ)에 대한 98% 신뢰구간을 구하고,
# 평균교통소음정도가 60 을 초과한다고 주장할 수 있는지
# 유의수준 5% 에서 가설검정을 실시하라. (p.314)
noise = np.array([55.9, 63.8, 57.2, 59.8, 65.7, 62.7, 60.8, 51.3, 61.8, 56.0,
66.9, 56.8, 66.2, 64.6, 59.5, 63.1, 60.6, 62.0, 59.4, 67.2,
63.6, 60.5, 66.8, 61.8, 64.8, 55.8, 55.7, 77.1, 62.1, 61.0,
58.9, 60.0, 66.9, 61.7, 60.3, 51.5, 67.0, 60.2, 56.2, 59.4,
67.9, 64.9, 55.7, 61.4, 62.6, 56.4, 56.4, 69.4, 57.6, 63.8])
2 . 통 계 적 추 론 ( Statistical Inference )
표본이 갖고 있는 정보를 분석하여 모수에 관한 결론을 유도하고,
모수에 대한 가설의 옳고 그름을 판단하는 것을 말한다.
모집단의 일부인 표본으로부터 전체 모집단의 성질을 추론해내는 것이므로
100 % 확실하다고 할 수는 없다.
따라서 통계적인 추론을 할 때에는
그 결론의 부정확한 정도를 반드시 언급하여야 하는데
이러한 정도를 수치로 표시할 수 있게 하는 도구로
앞에서 공부한 확률론과 표준분포 등이 이용된다.
통계적 추론에는 두 가지 주요 방법이 있다:
- 모수의 추정
- 모수에 대한 가설 검증
3 . 모 평 균 의 추 정 ( Estimation of Parameters )
모수 중 하나로 포함되는, 모집단의 평균에 대한 점추정과 구간추정을 다루고자 한다.
3 - 1 . 점 추 정 ( Point Estimation )
추정하고자 하는 하나의 모수에 대해,
여러 개의 확률변수를 사용하여 하나의 통계량을 만들고,
주어진 표본으로부터 그 값을 계산하여 하나의 수치를 제시하는 과정.
- 모수 ( Parameter ) : 모집단의 실제 값으로, 우리가 알고 싶어하는 대상.
- 추정량 ( Estimator ) : 모수를 측정하기 위해 만들어진 통계량.
- 추정치 ( Estimate ) : 주어진 관측값으로부터 계산된 추정량의 실제 값.

추정량은 하나의 확률변수이므로,
추출된 표본의 따라 그 값이 달라진다.
수치들의 변화의 정도는 추정량의 정확도와 관계가 있다.
이 정확도를 측정하는 도구 중 하나가 표준오차 ( 추정량의 표준편차 ) 이다.
3 - 2 . 표 준 오 차 ( Standard Error, SE )
추정량의 정확도를 평가하는 데 중요한 지표이며,
값이 작을수록 추정량이 모집단 모수를 더 정확하게 반영한다고 할 수 있다.

표본평균을 가지고 μ 를 추정할 경우,
n 이 클수록 표준오차가 작아져 좀 더 정확한 추정이 가능하다.
그러나 표준오차 계산 시 σ 가 주어지지 않는 경우가 있다.
이 경우, σ 를 표본표준편차로 추정하여 사용할 수 있다.


3 - 3 . 구 간 추 정 ( Interval Estimation )
추정량의 분포를 이용하여 표본으로부터 모수 값을
포함하리라고 예상되는 구간을 제시하는 것.
이때 제시되는 구간을 신뢰구간이라고 한다.
3 - 4 . 신 뢰 구 간 ( Confidence Interval )
모집단의 어떤 모수를 추정하기 위해 계산된 범위.
신뢰구간은 ( L , U )의 형태로 이루어지며,
여기서 L 과 U 는 표본으로부터 계산된 통계량이다.
- L ( Lower bound ) : 신뢰구간의 하한값
- U ( Upper bound ) : 신뢰구간의 상한값
따라서 표본마다 계산되는 신뢰구간은 서로 다를 수 있다.
가장 확실한 신뢰구간은 항상 모수를 포함하는 구간이다.
그러나 이는 이론적으로는 가능하지만 실질적으로는 불가능하다.
그렇게 되기 위해서는 신뢰구간이 상당히 길어질 수 밖에 없다.

항상 모수를 포함하는 신뢰구간은 실질적으로 너무 넓어서 유용하지 않다.
모수에 대한 정확한 정보를 얻으려면 신뢰구간을 가능한 한 줄일 필요가 있다.

실용적인 측면에서 신뢰구간을 적절히 좁히기 위해, " 모든 표본에서 항상 모수를 포함해야 한다 " 는 엄격한 조건을 완화하고,
대부분의 경우에서 모수를 포함하도록 설정하는 것이 필요하다.

이때에 모수를 포함할 확률을 신뢰수준 ( Level of Confidence )
또는 신뢰도라고 한다.
3 - 5 . 모 평 균 μ 에 대 한 신 뢰 구 간
여기에서는 신뢰구간을 계산하는 두 가지 경우를 설명한다:
( 1 ) 모집단의 표준편차 를 알고 있는 경우:
정규분포 개념을 이용하여 신뢰구간을 계산한다:
신뢰수준 95 % 에 해당하는 정규분포의 임계값 를 사용하여 신뢰구간의 범위를 설정한다.
예시 : α = 0.05 일 때, Z ₀.₀₅ / ₂ = Z ₀.₀₂₅ = 1.96

- 정규분포는 평균 μ 와 표준편차 를 알 때, 그 분포의 형태가 완전히 결정된다.
- 평균 μ 를 중심으로 좌우 대칭이며, 가 클수록 분포가 넓어진다.
이 특성 덕분에, 정규분포는 모수에 대해 많은 정보를 제공할 수 있다.
모집단이 정규분포를 따른다면, 표본 평균의 분포 역시 정규분포를 따른다.
위의 식에서 괄호 안에 부등식을 풀어 쓰면:

위 식을 μ 에 대해 정리하면:

따라서:

( 2 ) 모집단의 표준편차 를 모르는 경우:
일반적인 경우에 관심있는 모집단은 그 분포나 표준편차가 알려져 있지 않다.
이런 경우, 9장에서 다룬 중심극한정리를 이용한다.

- 이 경우에도, 확률 1 − α 는 근사적으로 얻어진다.
- n 이 클 때는

3 - 6 . 신 뢰 구 간 의 의 미
- 이 그래프는 주어진 모수에 대해 95% 신뢰구간을 표시하였다.
- 주어진 모수 (평균 100, 표준편차 10), 표본 크기 15를 사용하여 총 25개의 표본을 추출하였다.
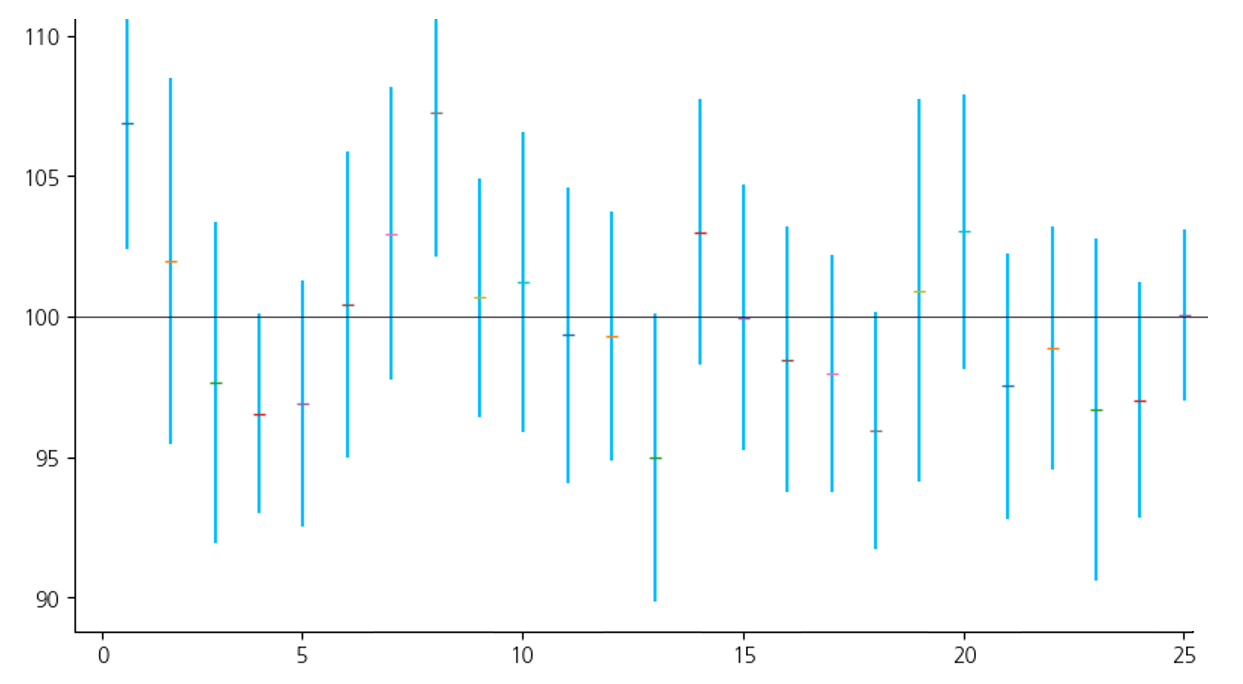
위 그래프와 같은 방식으로 표본을 계속 추출하고 신뢰구간을 계산하면,
그 신뢰구간들이 모평균을 포함하는 비율이 95% 에 가까워지는 것을 확인할 수 있다.
3 - 7 . 표 본 크 기 의 결 정
많은 수의 표본을 추출하여 신뢰구간을 생성하는 것은 시간과 비용이 많이 소모된다.
따라서 우리가 원하는 정확도를 얻을 수 있는 범위 내에서
표본의 크기를 줄이는 것이 바람직하다.
오차가 d 이하가 될 확률이 최소한 100 ( 1 − α ) % 가 되려면:

표준화된 확률변수의 분포가 표준정규분포를 따르므로:
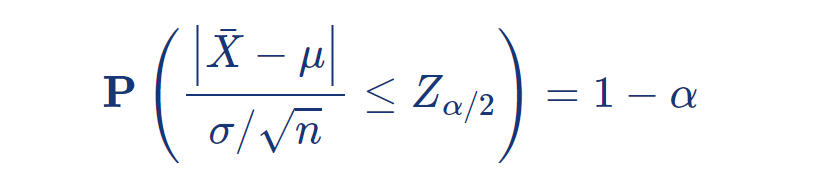
위 사실로부터 아래 식이 성립해야 하며:

이를 n 에 대하여 풀면 아래 식을 만족해야 한다:

만약 모집단이 정규분포라는 가정이 없다면
표본의 크기는 중심극한정리를 이용할 수 있도록 30 이상이 되어야 한다.
4 . 모 평 균 에 대 한 검 정
통계적 추론 중 하나인 모수에 대한
가설 검증 ( Testing Statistical Hypotheses ) 에 대해 다루고자 한다.
4 - 1 . 가 설 ( H y p o t h e s e s )
가설검증에는 2 개의 가설이 있다.
- 대립가설 ( Alternative Hypothesis ; H ₁ ) :
- 입증하여 주장하고자 하는 가설.
- 귀무가설 ( Null Hypothesis ; H ₀ ) :
- 대립가설을 입증할 수 없을 때, 대립가설을 무효화하면서 받아들이는 가설.
4 - 2 . 오 류 의 종 류
가설검증에서 내리는 판단이란 다음 2 가지 형태 중 하나로 나타난다.

- 제1종 오류 ( Type I Error ; α ) :
- 귀무가설이 참임에도 기각할 확률.
- 예시 : 실제로 신약이 효과가 없는데, 효과가 있다고 결론 내리는 경우.
- 제2종 오류 ( Type II Error ; β ) :
- 대립가설이 참임에도 기각할 확률.
- 예시 : 실제로 신약이 효과가 있는데, 효과가 없다고 결론 내리는 경우.
4 - 3 . 검 정 통 계 량 ( Test Statistic )
표본 데이터를 요약하여 귀무가설을 검정하는 데 사용하는 값.
귀무가설이 참이라는 가정 하에 표본에서 계산된 값으로,
이 값이 귀무가설 하에서 얼마나 극단적인지를 평가한다.
4 - 4 . 기 각 역 ( Critical Region )
귀무가설을 기각할 수 있는 값들의 집합.
검정 통계량이 기각역에
- 속할 경우 귀무가설을 기각한다.
- 아닐 경우 귀무가설을 기각하지 않는다.

가장 바람직한 기각역이란 아래 두 확률을 최소화하는 것이 될 것이다.
- α : 제 1 종 오류를 범하게 될 확률.
- β : 제 2 종 오류를 범하게 될 확률.
위 두 확률은 다음과 같은 특징이 있다:
( 1 ) α 와 β 는 서로 반비례 관계에 있다.
는 너무 크게 설정하지 않는 것이 좋다.
너무 큰 α 는 제1종 오류의 확률을 높여 잘못된 결론을 내릴 가능성을 높인다.
이를 방지하기 위해, 유의수준이라는 상한선을 둘 수 있다.
4 - 5 . 유 의 수 준 ( Significance Level )
일반적으로 사용되는 유의수준은 0.05 ( 5% ) 또는 0.01 ( 1% ) 이다.
이는 연구자가 제1종 오류의 확률을 낮추어 신뢰할 수 있는 결과를 얻기 위함이다.
- 0.05 ( 5% ) : 가장 흔히 사용되는 유의수준. 제1종 오류를 5% 로 제한.
- 0.01 ( 1% ) : 더 엄격한 기준으로, 제1종 오류를 1% 로 제한.
- 0.10 ( 10% ) : 덜 엄격한 기준으로, 제1종 오류를 10% 로 제한.
- 양측 검정 ( Two — tailed Test ) :
- 유의 수준 α 는 두 방향 ( 양쪽 끝 ) 에 분배되어 α / 2 씩 기각역을 형성한다.
- 단측 검정 ( One — tailed Test ) :
- 유의 수준 α 는 한 방향에 집중되어 기각역을 형성한다.
4 - 6 . 모 평 균 μ 에 대 한 검 정
표본의 크기가 클 때 모평균 μ 에 대한
가설 H ₀ : μ = μ₀ 을 검정하기 위한 검정통계량은 다음과 같다:

검정통계량은 H ₀ 이 맞을 때 N ( 0 , 1 ) 을 따른다.
각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

4 - 7 . 유 의 확 률 ( Significance Probability )
주어진 검정통계량의 관측치로부터 H ₀ 을 기각하게 하는 최소의 유의수준.
- P – 값 ( P – Value )
일반적으로 유의확률은 주어진 관측값을 경계점으로 하는 기각역의 유의수준으로 얻어진다.
Z = z 일 때 각 기각역의 형태에 따라 P – 값을 구하는 식을 정리하면 다음과 같다:

5 . 모 비 율 에 대 한 추 론
모집단에서 특정 속성을 가진 개체의 비율을 추정하거나 검정하는 것을 의미한다.
5 - 1 . 점 추 정
모비율에 대한 추정량으로 표본비율을 사용할 수 있다:
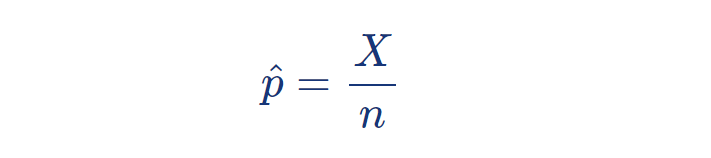
점추정량이 결정되면 그 추정량의 정확도를 알기 위해 표준오차를 계산할 필요가 있다.
모집단의 크기가 매우 커서 그에 비해 표본의 크기가 작은 경우,
X 의 분포는 반복 횟수 n , 성공의 확률 p 인 이항분포가 된다.
따라서, X 의 기댓값과 분산는 아래와 같다:
- E ( X ) = np
- Var ( X ) = npq
표본비율의 표준오차는 다음과 같이 계산된다:
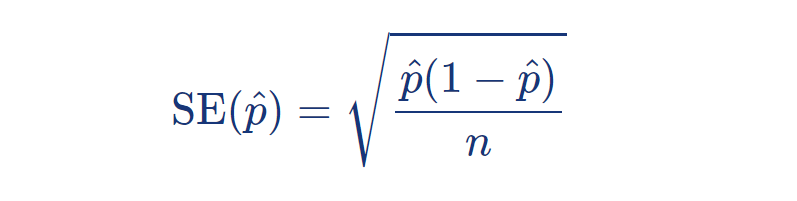
표본비율의 분산 은 아래 식과 같다:

5 - 2 . 구 간 추 정
모비율 P 에 대한 구간추정을 하려면 P 의 추정량인 p̂ 의 분포를 알아야 한다.
X 의 분포는 이항분포를 따르므로, 중심극한정리를 이용하여
표본 비율 p̂의 분포를 근사적으로 정규분포로 취급할 수 있다:


5 - 3 . 신 뢰 구 간

5 - 4 . 표 본 크 기 의 결 정
오차가 d 이하가 될 확률이 최소한 100 ( 1 − α )% 가 되려면:


따라서, 표본 크기는 아래 식을 만족해야 한다:

5 - 5 . 모 비 율 p 에 대 한 검 정
표본 크기가 클 때 모비율 p 에 대한 가설 H ₀ : p = p ₀ 을
검정하기 위한 검정통계량은 다음과 같다:

검정통계량은 H ₀ 이 맞을 때 N ( 0 , 1 ) 을 따른다.
각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

예제 13의 ( 1 )
height 에 대한 요약 통계량 계산하기.
xbar_h = np.mean(height);print(xbar_h) # 평균
var_h = np.var(height, ddof=1);print(var_h) # 분산 (자유도 1 사용)
sd_h = np.std(height, ddof=1);print(sd_h) # 표준편차 (자유도 1 사용)
median_h = np.median(height);print(median_h) # 중앙값
min_h = np.min(height);print(min_h) # 최솟값
max_h = np.max(height);print(max_h) # 최댓값
sum_h = np.sum(height);print(sum_h) # 합계
n = height.size;print(n) # 데이터 개수
예제 13의 ( 2 )
신뢰구간을 구하기 위해, 아래 2가지 함수를 사용한다.
- 추정량의 표준오차를 구하는 함수.
- 정규분포의 백분위수 함수.
from scipy import stats
se_h = stats.sem(height);print(se_h) # 표본표준오차
z_alpha = stats.norm.ppf(1 - 0.05 / 2);print(z_alpha) # 95% 신뢰구간을 위한 z값
interval = z_alpha * se_h;print(interval) # 신뢰구간 계산을 위한 간격 계산
CI = [xbar_h - interval, xbar_h + interval];print(CI) # 신뢰구간
예제 14
검정하고자 하는 가설은 H ₀ : μ = 159 대 H ₀ : μ ≠ 159 이며,
표본의 크기는 30 이상이다.
zval = (xbar_h-159)/se_h;print(zval) # 가설 검정을 위한 z값
pval = 2 * (1 - stats.norm.cdf(zval));print(pval) # p값
## 해석: 계산된 p값이 상당히 커서 귀무가설을 기각할 수 없으므로
## 중학교 1학년 남학생의 평균키가 159와 차이가 난다고 판단할 수 있다.
예제 15의 ( 1 )
신뢰구간의 신뢰수준이 98% 이므로
α = 200 을 이용하여, 표준오차와 Z α / 2 를 계산하고,
이로부터 오차범위값과 모집단 μ 에 대한 98% 신뢰구간을 구한다.
xbar_n = np.mean(noise);print(xbar_n) # 평균
sd_n = np.std(noise,ddof=1);print(sd_n) # 표준편차 (자유도 1 사용)
n = noise.size;print(n) # 데이터 개수
검정하고자 하는 가설은 H ₀ : μ = 60 대 H ₁ : μ > 60 이며,
표본의 크기는 30 이상이다.
se_n = stats.sem(noise);print(se_n) # 표본표준오차
z_alpha = stats.norm.ppf(1 - 0.02 / 2);print(z_alpha) # 95% 신뢰구간을 위한 z값
interval = z_alpha * se_n;print(interval) # 신뢰구간 계산을 위한 간격 계산
Cl = [xbar_n - interval, xbar_n + interval];print(CI) # 신뢰구간
zval = (xbar_n-60) / se_n;print(zval) # 가설 검정을 위한 z값
pval = stats.norm.sf(np.abs(zval));print(pval) # p값
## 해석: P—값이 0.021로 0.05보다 작게 나왔으므로
## 유의수준 5% 에서 귀무가설을 기각할 수 있다.
## 그러므로, 평균교통소음정도가 60 보다 크다고 할 수 있다.
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)
P Hat Symbol (p̂) (wumbo.net)
참고용 블로그: 작은 숫자 특수문자 첨자 및 분수숫자 모음
교제: 통계학: 파이썬을 이용한 분석
'2024 - 1학기 > 데이터분석입문' 카테고리의 다른 글
| 12장: 두 모집단의 비교 (2) | 2024.07.31 |
|---|---|
| 11장: 정규모집단에서의 추론 (0) | 2024.07.28 |
| 9장: 표집분포 (8) | 2024.07.21 |
| 8장: 정규분포 (2) | 2024.07.18 |
| 7장: 이항분포와 그에 관련된 분포들 (4) | 2024.07.15 |