Reporting Date: July. 31, 2024
두 모집단의 비교를 위한 추론과정은
자료를 어떻게 수집하느냐에 따라 추론 방법이 달라진다.
대표적인 두 종류의 자료수집과정에 따른 추론방법을 다루고자 한다.
목차3. 두 개의 독립 표본
3-1. 모평균의 차에 대한 추론 (표본의 크기가 클 때)
3-2. 모평균의 차에 대한 추론 (표본의 크기가 작고, 표준편차가 같을 때)
3-3. 모평균의 차에 대한 추론 (표본의 크기가 작고, 표준편차가 다를 때)4. 짝비교 (Matched Pair Comparisons)
1 . 자 료 의 입 력
# 예제12: 산림자원의 현황을 파악하는데
# 인공위성에 설치된 특수한 스캐너를 이용하려 한다.
# 이 스캐너가 충분히 실제 지상의 상황을 반영하는가를 알아보기 위해서
# '숲이 있는 지역'과 '도시지역'을 지날 때의 스캐너의 수치를 비교하고자 한다.
# 두 지역에서 얻어진 스캐너 수치의 평균이 다르면
# 도시와 숲을 구별하는 데 스캐너가 사용될 수가 있다고 한다.
# 자료로부터 평균 차의 95% 신뢰구간을 구하고, 스캐너의 사용이 가능한지를 판단하라. (p.387)## 교재 출처 최하단에 표시 ##
import numpy as np
from scipy import stats
import math
# 숲이 있는 지역을 지날 때의 스캐너 수치:
x = np.array([77, 77, 78, 78, 81, 81, 82, 82, 82, 82,
82, 83, 83, 84, 84, 84, 84, 85, 86, 86,
86, 86, 86, 87, 87, 87, 87, 87, 87, 87,
89, 89, 89, 89, 89, 89, 89, 90, 90, 90,
91, 91, 91, 91, 91, 91, 91, 91, 91, 91,
93, 93, 93, 93, 93, 93, 94, 94, 94, 94,
94, 94, 94, 94, 94, 94, 94, 94, 95, 95,
95, 95, 95, 96, 96, 96, 96, 96, 96, 97,
97, 97, 97, 97, 97, 97, 97, 97, 98, 99,
100, 100, 100, 100, 100, 100, 100, 100,
100, 101, 101, 101, 101, 101, 101, 102,
102, 102, 102, 102, 102, 103, 103, 104,
104, 104, 105, 107])
# 도시지역을 지날 때의 스캐너 수치:
y = np.array([71, 72, 73, 74, 75, 77, 78, 79, 79, 79,
79, 80, 80, 80, 81, 81, 81, 82, 82, 82,
82, 84, 84, 84, 84, 84, 84, 85, 85, 85,
85, 85, 85, 86, 86, 87, 88, 90, 91, 94])
2 . 통 계 용 어
비교 연구 시 자주 사용되는 통계용어.
- 실험단위 ( Experimental Unit ) : 실험의 대상.
- 반응값 ( Response ) : 실험 후 얻어지는 수치.
- 처리 ( Treatment ) : 비교하고자 하는 특성.
예제12를 위 통계용어로 다음과 같이 설명할 수 있다:
숲 지역 ⇨ 처리 1 , 도시 지역 ⇨ 처리 2
각각의 스캐너 측정값 ⇨ 실험단위
그 측정값의 수치 ⇨ 반응값
3 . 두 개 의 독 립 표 본
독립인 두 개의 표본으로부터 두 모집단, 혹은
두 가지의 처리효과를 비교하는 통계추론의 방법.
다음은 두 모집단으로부터 추출된 표본과
그로부터 계산되는 통계량을 정리한 것이다:


여기서 우리의 관심사는 두 모집단의 평균 반응값의 차이다.
3 - 1 . 모 평 균 의 차 에 대 한 추 론
두 모평균의 차 ( μ 1 – μ 2 ) 에 대한 추론을 위해서는 두 표본평균의 차 ( x̄ – ȳ )를 이용한다.
두 표본의 크기 n 1, n 2 가 모두 큰 경우 ( 30 이상 )
중심극한정리에 의해 두 표본평균은 근사적으로 정규분포를 따른다:

평균이 이고, 분산이 인 정규분포를 따른다:
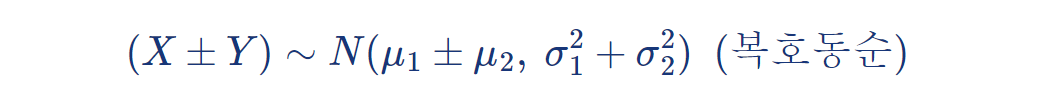
- 복호동순 : 식에서 부호를 2 개 이상 사용할 때, 부호를 앞에서부터 같은 순서로 적용하는 것.
따라서, 두 독립적인 정규분포 변수의 차를 표준화하면 표준정규분포를 따르게 된다:

위 분포를 바탕으로 ( μ 1 – μ 2 ) 에 대한 신뢰구간은 다음과 같다:

두 표본의 크기 n 1, n 2 가 모두 30 이상일 때,
가설 H 0 : μ 1 – μ 2 = δ 0 에 대한 검정통계량은 다음과 같다:

검정통계량은 H 0 이 맞을 때 N ( 0 , 1 ) 을 따른다.
각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

3 - 2 . 모 평 균 의 차 에 대 한 추 론
표본의 크기가 작을 경우, 두 모집단에 대하여 정규분포와 표준편차에 대한 가정이 필요하다.
- 두 모집단이 모두 정규분포를 따른다.
- 두 모집단의 표준편차가 일치한다.

대부분의 경우, σ 를 모르므로 이를 추정하여야 한다.
σ 에 대한 정보는 편차제곱합에 모두 들어 있다.
따라서 이 두 제곱합을 더하여 각각의 자유도의 합으로 나누어 σ 2 추정량으로 사용하게 된다.
이를 공통분산 σ 2 의 합동추정량 ( Pooled Variance ) 이라 한다:

위 식을 이용하여, ( μ 1 – μ 2 ) 에 대한 표준화된 확률변수는 다음과 같다:

위 분포를 바탕으로 ( μ 1 – μ 2 ) 에 대한 신뢰구간은 다음과 같다:

두 모집단이 모두 정규분포를 따르고 두 모표준편차가 같은 때
가설 H 0 : μ 1 – μ 2 = δ 0 에 대한 검정통계량은 다음과 같다:

각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

3 - 3 . 모 평 균 의 차 에 대 한 추 론
표본의 크기가 작고, 두 모집단의 표준편차가 일치하지 않을 경우,
근사적으로 t 분포를 따르며, 자유도는 ( n 1 – 1 )과 ( n 2 – 1 ) 중 작은 값이다.
이 분포를 이용한 ( μ 1 – μ 2 ) 에 대한 추론방법은 다음과 같다:

- 신뢰구간의 경우, 그 구간이 넓어지는 경향이 있다.
- 따라서 실제 신뢰도는 100 ( 1 − α ) % 이상이 된다.
가설 H 0 : μ 1 – μ 2 = δ 0 에 대한 검정통계량은 다음과 같다:

- 검정의 경우, 기각역이 좁아지는 경향이 있다.
- 따라서 실제 유의수준이 α 이하가 되므로 귀무가설을 기각하지 못할 가능성이 높아진다.
4 . 짝 비 교 ( Matched Pair Comparisons )
실험 단위들이 비슷해야 한다는 점과 다양한 실험 단위들을 비교해야 한다는 점을 절충하는 접근법.
짝지워서 각각의 쌍으로 만드는 방법:
- 같은 쌍의 실험단위들은 서로 비슷해야 한다.
- 각 쌍 내에서 두 조건이 다르게 설정되어야 한다.
짝 비교를 시행할 때의 자료의 형태:

차의 표본평균과 분산은 다음과 같다:

- X i 와 Y i 는 서로 독립이 아니다.
- 서로 높은 상관관계를 가질 경우, 짝비교의 효과는 크다.
- 즉, 전체적인 변화의 폭 ( 변동성 ) 을 줄여 처리효과를 알아내기 수월한 짝비교를 할 수 있다.
모평균 δ 에 대한 100 ( 1 − α ) % 신뢰구간은 다음과 같다:

귀무가설 H 0 : δ = δ 0 에 대한 검정통계량은 다음과 같다:

자료가 짝지워져 있는 경우,
두 개의 처리를 어떻게 배정할 것인가가 전혀 문제되지 않는다.
자료가 짝지워져 있지 않은 경우,
- 여러 조건들이 확률적으로 같은 정도로 영향이 미치도록 해야 한다.
- (어느 한쪽의 처리에만 영향을 주지 않아야 한다.)
이와 같이 무작위로 배정하는 것을 랜덤화 ( Randomization ) 라고 한다.
5 . 두 모 비 율 의 차 에 대 한 추 론
두 모집단의 비율을 비교하는 추론하는 방법.
관심의 대상이 되는 어떤 특성의 모집단 1 의 비율을 p 1, 모집단 2 의 비율을 p 2 라고 할 때
두 모집단으로부터 크기가 n 1, n 2 인 표본을 추출하여 각각 특성이
A 인 것과 A 가 아닌 것으로 분류하였다고 가정한다.

이때 A 를 ' 성공 ', A 가 아닌 것을 ' 실패 ' 라고 하고
두 표본의 성공의 개수를 각각 X, Y 표현한다.
두 모집단의 특성 A 의 비율을 각각 p 1, p 2 라고 하면
그 추정량은 각 표본으로부터 표본의 비율을 사용하게 된다:

( p 1 – p 2 ) 에 대한 추론을 하기 위해서는 ( p̂ 1 – p̂ 2 ) 의 분포를 알아야 한다.
표본의 크기 n 1, n 2 가 큰 경우, 아래 식이 근사적으로 성립한다:

아래 식도 표본이 서로 독립이므로 정규분포로 근사된다:
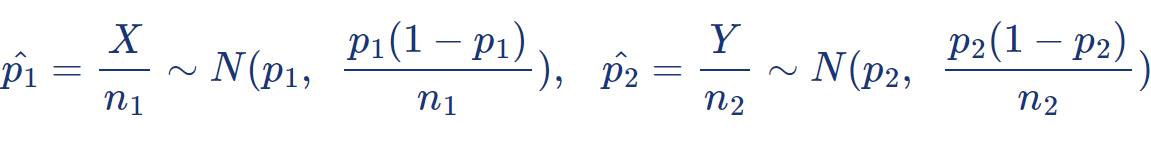
따라서 이를 표준화하면:

위 식을 이용하여 ( p 1 – p 2 ) 에 대한 ( 1 − α ) % 신뢰구간은 다음과 같다:
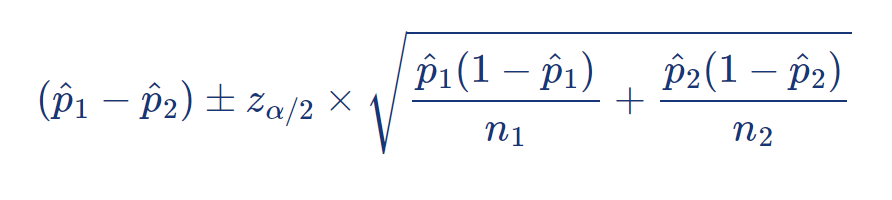
신뢰구간을 계산할 때, ( 제곱근 속의 ) 실제 모평균 차이 p 1, p 2 는 미지수이므로,
이를 표본 비율의 차이 p̂ 1, p̂ 2 로 대체하여 계산한다.
5 - 1 . 두 모 비 율 의 검 정
표본의 크기가 클 때 두 모비율이 같은지를 검정하는 방법은
두 비율의 차이에 대한 검정을 통해 이루어진다.
귀무가설 H 0 : p = p 0 을 검정하기 위해 ( p̂ 1 – p̂ 2 ) 을 이용하게 된다.
이 가설이 맞을 경우의 통계량 분포는 다음과 같다:

통합된 두 표본으로부터 이를 추정하면:

위 과정을 바탕으로 검정통계량을 정리할 수 있다:

p̂ 는 귀무가설하에서의 공통비율 p 의 추정량이고,
검정통계량은 H 0 가 맞을 때 근사적으로 N ( 0, 1 ) 을 따른다.
각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

예제 12의 ( 1 )
추정량의 표준오차 ( se ) 를 계산하기 위해
두 변수의 요약통계량 ( s 12, s 22 ) 을 구하는 파이썬 함수를 사용할 수 있다.
var1 = np.var(x, ddof=1);print(var1) # x의 표본 분산 (자유도=1)
var2 = np.var(y, ddof=1);print(var2) # y의 표본 분산 (자유도=1)
n1 = len(x);print(n1) # x의 데이터 수
n2 = len(y);print(n2) # y의 데이터 수
se = math.sqrt(var1 / n1 + var2 / n2);print(se) # 표준오차
예제 12의 ( 2 )
모평균의 차 μ 1 – μ 2 에 대한 95% 신뢰구간을 구하라.
# 신뢰수준 95%에 해당하는 z–점수
z_alpha = stats.norm.ppf(1 - 0.05 / 2);print(z_alpha)
interval_z = z_alpha * se; print(interval_z) # 신뢰구간 범위
# x와 y의 평균을 계산
xbar1 = np.mean(x); print(xbar1)
xbar2 = np.mean(y); print(xbar2)
# 두 평균의 차이를 계산
diff = xbar1 - xbar2; print(diff)
# 신뢰구간
Cl_1 = [diff - interval_z, diff + interval_z]; print(Cl_1)
## 해석: 95%의 신뢰구간이 0을 포함하지 않으므로 (양측검정에서)
## 유의수준 5%에서 두 수치가 같다는 귀무가설 (H₀ : μ1 = μ2) 을 기각할 수 있다.
예제 12의 ( 3 )
두 모집단이 모두 정규분포를 따르고, 분산이 같다는 가정 하에서
합동분산추정량 및 추정량의 표준오차를 구하라.
# 합쳐진 분산 계산
spooled = ((n1 - 1) * var1 + (n2 - 1) * var2) / (n1 + n2 - 2); print(spooled)
# 합쳐진 표준 오차 계산
se_spooled = math.sqrt(spooled) * math.sqrt(1 / n1 + 1 / n2); print(se_spooled)
예제 12의 ( 4 )
위 결과를 바탕으로 t – 분포의 백분위수 함수를 이용하여 95% 신뢰구간을 구하라.
# 신뢰수준 95%에 해당하는 t–점수
t_alpha = stats.t.ppf(1 - 0.05 / 2, n1 + n2 - 2); print(t_alpha)
# 신뢰 구간의 범위
interval_t = t_alpha * se_spooled; print(interval_t)
# 신뢰구간
Cl_2 = [diff - interval_t, diff + interval_t]; print(Cl_2)
## 해석: (2)번의 정규분포를 이용한 신뢰구간보다
## 오차범위 값인 interval_t가 더 크므로 신뢰구간이 더 넓어졌음을 알 수 있다.
## 이는 t–분포의 백분위수 값이 (정규분포의 백분위수 값보다) 더 크기 때문이다.
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)
Symbols (wumbo.net)
'2024 - 1학기 > 데이터분석입문' 카테고리의 다른 글
| 14장: 분산분석 (2) | 2024.08.08 |
|---|---|
| 13장: 회귀분석 (2) | 2024.08.05 |
| 11장: 정규모집단에서의 추론 (0) | 2024.07.28 |
| 10장: 통계적 추론 (4) | 2024.07.25 |
| 9장: 표집분포 (8) | 2024.07.21 |