Reporting Date: August. 5, 2024
두 변수 간의 직선 관계를 설명하는 단순선형회귀모형에서의
추정, 검정, 예측 등에 대해 다루고자 한다.
목차
1. 자료의 입력
2. 단순선형회귀모형 (Simple Linear Regression Model)
3. 최소제곱법 (Least Squares Method)
3-1. 예측값 (Fitted Value) & 잔 차 (Residual)
3-2. 잔차제곱합 (Residual Sum of Squares)
3-3. 평균제곱오차 (Mean Squared Error, MSE)
4. 단순선형회귀모형에서의 추론
4-1. 기울기에 대한 추론
4-2. 절편에 대한 추론
4-3. 평균반응에 대한 추론
4-4. 반응변수값 Y의 예측
5. 선형관계의 강도
5-1. 총제곱합 (Total Sum of Squares, SST)
5-2. 회귀제곱합 (Regression Sum of Square, SSR)
5-3. 결정계수 (Coefficient of Determination, R ²)
6. 전차의 검토
6-1. 잔차와 예측값의 산점도
6-2. 잔차와 독립변수값의 산점도
6-3. 오차의 정규성 검정
6-4. 오차의 독립성 검정
예제9의 (1)
예제9의 (2)
예제9의 (3)
1 . 자 료 의 입 력
## 교재 출처 최하단에 표시 ##
# 예제 9: 4장의 예제 5에 주어져 있는 자료에 대하여 키가 주어질 때
# 몸무게를 예측하기 위한 회귀분석을 하라.
#-----------------------------------------------------------------------
import numpy as np
height = np.array([181, 161, 170, 160, 158, 168, 162, 179, 183, 178,
171, 177, 163, 158, 160, 160, 158, 173, 160, 163,
167, 165, 163, 173, 178, 170, 167, 177, 175, 169,
152, 158, 160, 160, 159, 180, 169, 162, 178, 173,
173, 171, 171, 170, 160, 167, 168, 166, 164, 173,
180])
weight = np.array([78, 49, 52, 53, 50, 57, 53, 54, 71, 73,
55, 73, 51, 53, 65, 48, 59, 64, 48, 53,
78, 45, 56, 70, 68, 59, 55, 64, 59, 55,
38, 45, 50, 46, 50, 63, 71, 52, 74, 52,
61, 65, 68, 57, 47, 48, 58, 59, 55, 74,
74])
2 . 단순선형회귀모형 ( Simple Linear Regression Model )
두 개의 변수 ( x, y ) 가 주어진 경우에 한 변수로부터 다른 변수를 예측하거나,
두 변수 사이의 관계를 규명하는 데 회귀분석의 방법이 이용된다.


확률변수 Y 를 (1)독립변수 x , (2)확률변수 ε ( 오차 ) 에 의해 설명되는 종속변수라고 하면
그 직선의 관계는 다음과 같이 표현될 수 있다:

위 식은 선형 회귀 분석에서 가장 기본적인 형태의 회귀 모델을 나타낸다.
이 식의 주요 조건은 다음과 같다:


위 회귀모형으로부터 독립변수가 x ᵢ 일 때 종속변수 Y 는
평균이 β ₀ + β ₁ x ᵢ 이고 분산이 σ ² 인 정규분포를 따른다는 것을 알 수 있다:

위 회귀직선을 추정하는 방법은 다음과 같이 요약할 수 있다:
두 변수 사이의 모회귀직선 ( Population Regression Line ) 이라고 하는
( 1 ) 미지의 직선 관계 y = β ₀ + β ₁ x 를 가정하고,
( 2 ) 두 변수의 자료 ( x ₁, y ₂ ), …, ( x ₙ, y ₙ ) 를 이용하여
( 3 ) 미지의 회귀 모수 β ₀ , β ₁ 를 추정한 후에
( 4 ) 이들을 이용하여 회귀직선을 추정하게 된다.
3 . 최 소 제 곱 법 ( Least Squares Method )
통계학과 회귀 분석에서 사용되는 방법으로,
주어진 데이터에 가장 잘 맞는 모형을 찾기 위해 회귀 계수를 추정하는 기법이다.
이 방법의 핵심은 관측된 데이터와 모형에 의해 예측된 값 간의 오차를 최소화하는 것이다.

최소제곱법은 편차의 제곱합을 최소화하는 모수의 값을 찾아
모수의 추정값으로 사용하는 방법이다:

이때 D 를 최소화하는 b ₀ , b ₁ 을 찾게 되는데
이 값을 최소제곱추정량 ( Least Squares Estimator ) 이라고 한다.
따라서 최소제곱법에 의한 추정직선은 다음과 같다:

단순회귀모형에서의 추정량을 구하기 전에 계산의 편의를 위하여
다음과 같이 기호를 정의하여 사용한다:



단순선형회귀모형에서 최소제곱추정량은
D 를 편미분 ( Partial Derivative ) 하여 얻을 수 있다:


β ₀ 에 대한 편미분
오차 제곱합을 β ₀ 에 대해 편미분하면:

위 식을 0 으로 설정하면:

위 식을 정리하면:

β ₁ 에 대한 편미분
오차 제곱합을 β ₁ 에 대해 편미분하면:

위 식을 0 으로 설정하면:
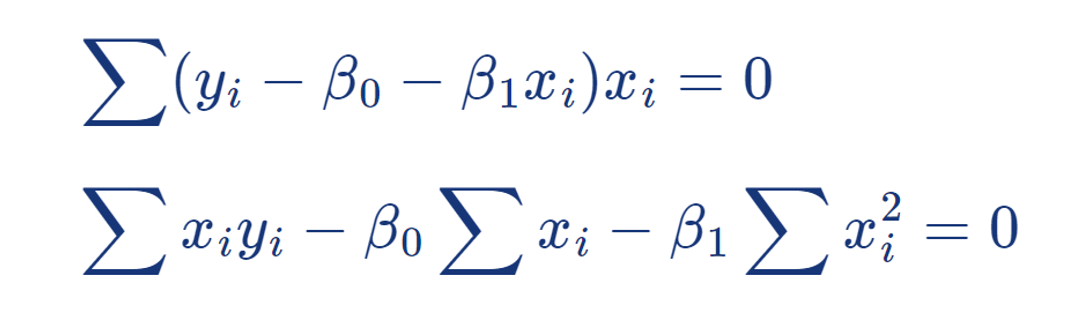
최적의 β ₀ , β ₁ 추정량
편미분 결과를 통해 다음의 정상 방정식을 얻는다:

위 두 방정식을 풀면, 최적의 β ₀ , β ₁ 를 얻을 수 있다:

3 - 1 . 예 측 값 ( Fitted Value ) & 잔 차 ( Residual )
회귀 모형에 의해 주어진 독립 변수 x ᵢ 에 대한 종속 변수의 예상 값을 예측값,
실제 관측값 y ᵢ 과 예측값 ( 추정량 ) ŷ ᵢ 간의 차이를 잔차라고 한다.

단순선형회귀모형에서 최소제곱추정량에 의한 잔차는
양수 또는 음수를 가지며, 잔차의 합은 0 이 된다:

잔차는 오차의 추정량이므로 오차의 분산을 추정하기 위해
관측되지 않는 확률변수인 오차 대신 잔차를 사용한다.
잔차를 사용하려면 우선 잔차 제곱합을 구해야 한다.
3 - 2 . 잔 차 제 곱 합 ( Residual Sum of Squares )
이것은 오차에 기인한 제곱합 ( Sum of Squares due to Error, SSE ) 이라고도 한다:

3 - 3 . 평 균 제 곱 오 차 ( Mean Squared Error, MSE )
오차의 분산 σ² 의 추정량으로 잔차제곱합을 n – 2 로 나눈 값을 사용하며,
이와 같이 정의된 σ² 의 추정량을 s ² 으로 표시한다:

두 개의 모수 β ₀ , β ₁ 를 추정하는 과정에서
데이터의 정보가 일부 소모되므로, 잔차의 자유도는 n – 2 로 감소된다.
감소된 자유도를 이용하면, 잔차의 분산을 무편향 추정량으로 만들 수 있으며,
결과적으로, 평균제곱오차 (MSE) 는 실제 모집단 분산과 거의 근사하게 추정된다.
오히려 n 으로 나누었을 때 자유도 소모를 반영하지 못해
구하고자 하는 추정값보다 낮게 나올 수 있다.
4 . 단 순 선 형 회 귀 모 형 에 서 의 추 론
이제 구해진 추정량에 대한 추론을 다루고자 한다.
( 만일 결과에 대한 해석에 더 관심이 있다면 추론은 생략해도 무관하다. )
단순선형회귀모형에서의 추론은 모델의 적합성을 평가하고,
회귀 계수에 대한 가설 검정 및 신뢰 구간을 설정하는 과정이다.
이를 위해서는 최소제곱추정량의 기울기를 구해야 한다.
4 - 1 . 기 울 기 에 대 한 추 론
기울기에 대한 추론은 추정량을 바탕으로 이루어진다.
추정량은 정규분포를 따르는 관측값 y 들의
선형결합으로 이루어져 있으므로 정규분포를 따르게 된다:


결과적으로, 10장의 모평균에 관한 추론과 흡사한 과정을 따르게 된다.
추정량에 대한 표준오차는 다음과 같다:
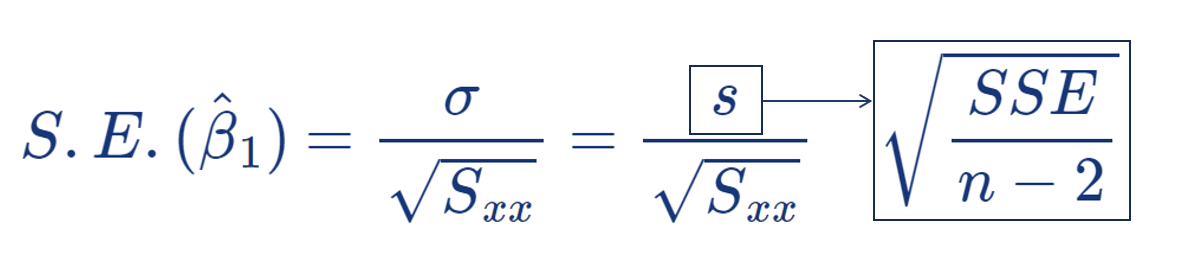
추정량에 대한 표본분포는 다음과 같다:

각 대립가설에 대하여 유의수준 α 를 갖는 기각역은 다음과 같다:

위 표본분포 식을 이용하여
β ₁ 의 100 ( 1 − α ) % 신뢰구간은 다음과 같다:
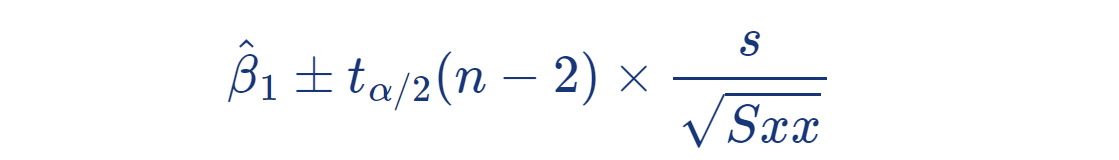
만일 H ₀ : β ₁ = 0 일 경우, 독립 변수 x 가
종속 변수 y 를 예측하는 데 아무런 도움을 주지 못한다는 것을 의미한다.
이는 두 변수 사이에 선형적인 관계가 없으며,
종속 변수를 예측할 때 독립 변수의 사용이 효과적이지 않으므로,
회귀 모형의 유용성이나 의미가 부족하다고 해석할 수 있다.
문제는 위 검정 결과를 해석할 때 귀무가설이 기각되지 않을 경우,
선형성이 없다고 잘못 결론을 내릴 수 있다.
그러므로 이 경우에는 직선관계가 없다고 해석해야 하며,
(두 변수 사이에 관계에 대해서는) 산점도를 통해 곡선관계가 있는지를 확인해야 한다.
4 - 2 . 절 편 에 대 한 추 론
위 문제를 보완하기 위해 절편에 대한 추론이 이루어진다.
추정량에 대한 표준오차는 다음과 같다:

추정량에 대한 표본분포는 다음과 같다:

위 표본분포 식을 이용하여
β ₀ 의 100 ( 1 − α ) % 신뢰구간은 다음과 같다:

위 신뢰구간의 경우, 검정의 결과를 간접적으로 평가하는 것이 가능하다.
예를 들어 95% 신뢰구간에서 0 이 포함된다면 절편이 0 이라는 의미이므로
가설 H ₀ : β ₀ = 0 을 기각할 수 없다는 것을 알 수 있다.
4 - 3 . 평 균 반 응 에 대 한 추 론
독립 변수의 특정한 값 x* 에 대응되는 종속 변수의 기댓값
ŷ* = β ₀ + β ₁ x* 에 대한 추정 및 그에 관련된 추론을 다루고자 한다.
추정량에 대한 표준오차는 다음과 같다:

추정량에 대한 표본분포는 다음과 같다:

위 표본분포 식을 이용하여
ŷ* 의 100 ( 1 − α ) % 신뢰구간은 다음과 같다:

신뢰구간의 폭은 아래와 같은 관계를 가진다:

자료의 범위를 크게 벗어나는
평균반응, 반응변수에 대한 추정은 주의해야 한다.
이러한 독립변수의 값의 평균반응에 대한 추정이
표준편차가 커짐으로써 정확도가 떨어진다는 것 이외에
추정하는 모형 자체에도 문제가 있을 수 있다.
이 경우, 전체적인 경향이 직선이 아닌 관계를 고려할 수 있으며,
올바른 추정을 위해 더 많은 데이터를 수집하거나,
더 넓은 범위의 독립 변수 값을 고려하는 작업이 필요하다.
4 - 4 . 반 응 변 수 값 Y 의 예 측
단일 반응값에 대한 추론을 원할 경우, 평균반응값의 오차를 더한 식이 된다.
이때 오차 ε 의 평균이 0 이므로
반응변수값의 추정량은 오차 ε 의 분산 σ² 에 의해 결정된다.
결론적으로, 예측값의 표준오차는
(평균반응값을 예측하는 경우보다) 조금 큰 값을 갖게 된다:

5 . 선 형 관 계 의 강 도
자료분석에서 적용되는 모형은 변수 간의 관계를
간단한 함수 관계로 표현하여 근사적으로 파악하려는 접근방법이다.
따라서 주어진 자료를 어떤 모형으로 표현할 때,
그 모형이 얼마나 적합한가를 측정하는 측도가 필요하다.
독립변수 x ᵢ 에서의 종속변수 y ᵢ 에 대응되는 예측값을 ŷ ᵢ 라고 하면
종속변수의 값은 다음과 같이 표현할 수 있다:

위 식에서 관심을 가져야 할 것은 마지막 항인 잔차 e ᵢ 로
잔차들의 값이 선형관계의 정도를 결정하므로
전체적으로 잔차들의 크기를 고려하는 잔차제곱합을 이용하여
자료의 전체적인 경향이 얼마만큼 벗어났는가를 측정하는 값으로 해석될 수 있다:
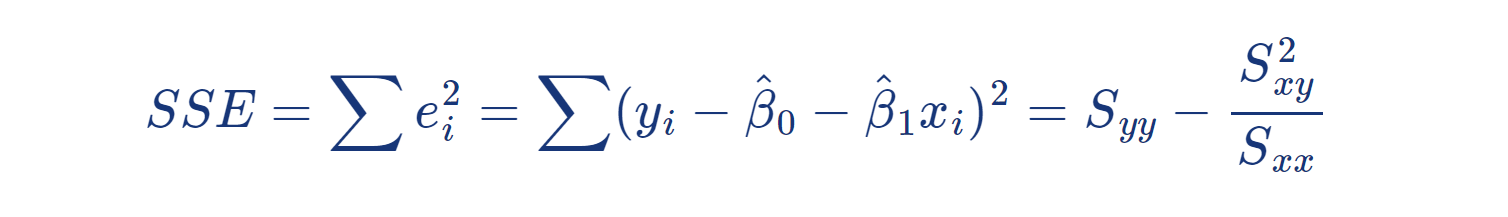
5 - 1 . 총 제 곱 합 ( Total Sum of Squares, SST )
한편 자료의 y 값들이 나타내는 변동의 크기는
y 의 총제곱합으로 측정될 수 있다:

SSE 가 y 의 총변동 SST 의 한 부분을 형성하게 된다:

5 - 2 . 회 귀 제 곱 합 ( Regression Sum of Square, SSR )
y 값들의 총변동 중 회귀모형에 의해서 설명될 수 있는 부분:

위 식으로로부터 선형모형이 주어진 자료에 적합하다는 것은
선형회귀모형으로 설명되는 SSR 부분이 y의 총변동 SST의
대부분에 해당되는 경우라고 해석할 수 있다.
따라서 이러한 예측값을 사용하는 데 따른 오차의 제곱합 SSE는
y의 총변동 SST 자체가 될 것이다.
결과적으로, 선형모형이 어느 정도 적합한가의 측도로서 y의 총변동 중
선형회귀모형에 의해 설명되는 변동부분의 비율 SSR / SST 를 이용할 수 있다.
5 - 3 . 결 정 계 수 ( Coefficient of Determination, R ² )

- 결정계수의 값은 항상 0 ~ 1 사이이며,
- 그 값이 1에 가까울 때, 선형회귀모형이 관측결과를 잘 설명해주는 경우라고 할 수 있다.
6 . 전 차 의 검 토
회귀모형에서의 추론은 가정된 모형이 타당할 때 그 추론에 대한 이론적 근거가 성립한다.
그러므로 회귀모형에서의 통계적 추론은 가정된 모형이 타당할 때에만 이루어져야 한다.
따라서, 모형에 가정에 대한 타당성 검토가 필요하다.
단순선형 회귀모형에서 오차 ε ᵢ 에 대한 가정은 다음과 같다:
(a) 평균은 0 이다.
(b) 독립성: 서로 독립이다.
(c) 등분산성: 분산은 σ ² 이다.
(d) 정규성: 정규분포 N ( 0 , σ ² ) 을 따른다.
위 모형의 절편에 의해 항상 가정 a가 성립하지만
나머지 가정들의 경우, 데이터의 특성과 모델 적합도에 따라 달라진다.
6 - 1 . 잔 차 와 예 측 값 의 산 점 도
수평축에 예측값, 수직축에 잔차로 하여 좌표평면을 형성하고
각 관측자료에 대응되는 잔차와 예측값을 이 좌표평면에 그려 넣어 작성한다.
이 산점도는 가정된 함수 관계의 부적당함 또는
가정된 등분산성이 위배됨을 지적하는 데 도움이 된다.
6 - 2 . 잔 차 와 독 립 변 수 값 의 산 점 도
수평축에 독립변수의 값, 수직축에 잔차의 값으로 정하여 작성된다.
수평축이 예측값으로 지정했을 때와 같은 방식을 따른다.
단, 독립변수가 2개 이상일 경우,
각 산점도로부터 나타나는 정보가 같지 않게 된다.
따라서, 두 종류의 산점도를 모두 조사하여 모형의 타당성을 검토해야 한다.
6 - 3 . 오 차 의 정 규 성 검 정
오차의 분포를 파악하는 방법으로 잔차의 히스토그램을 그려
정규분포를 따르는지 대략적으로 검토할 수 있다.
정규분포는 대칭이라는 성질을 가지고 있으므로, 만일 잔차의 히스토그램에서
분포의 모양이 대칭이라면 정규분포를 따른다고 예상할 수 있다.
다만 분포의 모양만으로 정규성을 판단하기에는 제한이 있다.
따라서, 보다 정확한 검정을 위해 8 장에서의 정규확률그림을 이용하여 잔차의 정규성을 검정할 수 있다.
6 - 4 . 오 차 의 독 립 성 검 정
회귀모형에서 가장 중요한 가정은 오차의 독립성이다.
이 가정을 보장하기 위해 각 추출 단위 ( Sampling Unit ) 가 독립이 되도록 설계하기도 한다.
그러나 시간에 따라 관측값을 얻는 경우, ( 물가, 주식가격 등 )
관측값의 순서를 임의로 정할 수 없으므로 가정이 위배되는 경우가 흔하다.
이 경우 독립의 가정을 확인하는 방법으로
연속적인 잔차의 쌍들의 산점도를 그려보는 것을 시도해볼 수 있다.
이 산점도에서 특별한 경향을 나타내지 않는 군집을 형성할 때 독립이라고 할 수 있다.
예제 9의 ( 1 )
회귀분석의 결과를 출력하라.
import pandas as pd
import statsmodels.formula.api as smf
# (height, weight)데이터 ▸▸▸ 딕셔너리 (저장).
d = {'height' : height, 'weight' : weight}
# 딕셔너리 ▸▸▸ DataFrame (변환).
dat = pd.DataFrame(data = d)
# 'weight' ▸ 종속 변수
# 'height' ▸ 독립 변수
# 위 조건을 바탕으로 선형 회귀 모델을 적합.
fit = smf.ols('weight ~ height', data = dat).fit()
print(fit.summary())
#--------------------------------------------------------------------------
## 해석: 추정된 Y 절편이 –100.7820이고,
## 추정된 키의 회귀계수 값이 0.9479이므로
## 회귀직선의 추정식은 몸무게(weight) = –100.782 + 0.9479 × 키(height)이다.
## 우측 최상단: R-squared(결정계수)의 값이 0.542이므로
## 몸무게의 변동 중에서 약 54.2%는 단순선형회귀 모형으로 설명될 수 있다.
## 가설 H₀: β₁ = 0 대 H₁: β₁ ≠ 0에 대한 검정통계량 관측값은
## height행의 t 열의 7.616으로 주어지고,
## 이에 따른 양측대립가설 P–값이 0.000으로 매우 작은 값으로 주어졌다.
## 따라서, 유의수준 0.01에서도 회귀모형의 기울기가 유의하다고 말할 수 있다.
예제 9의 ( 2 )
회귀계수의 신뢰구간을 계산하라.
# 회귀 계수의 95% 신뢰 구간 계산
conf_int = fit.conf_int(0.05)
예제 9의 ( 3 )
잔차도, 적합도, 전차 정규확률도를 그려라.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import statsmodels.api as sm
from scipy import stats
# 한글 폰트 설정 (사용할 한글 폰트의 이름을 가져온다)
font_name = font_manager.FontProperties(fname='C:/Windows/Fonts/malgun.ttf').get_name()
rc('font', family = font_name, size = 10) # 폰트 패밀리 및 크기 설정
rcParams['axes.unicode_minus'] = False # 마이너스 기호의 유니코드 문제를 방지
# 2x2 서브플롯 생성
plt.figure(figsize=(10, 8)) # 플롯의 크기 설정
# 첫 번째 서브플롯: 선형 회귀선 & 데이터 포인트
plt.subplot(2, 2, 1) # 2x2 그리드에서 첫 번째 위치에 서브플롯 생성
slope, intercept = np.polyfit(height, weight, 1) # 선형 회귀선 적합
abline_values = [slope * i + intercept for i in height] # 회귀선의 y값 계산
plt.plot(height, weight, 'o', label='Data') # 데이터 포인트 ▸ 산점도로 표시
plt.plot(height, abline_values, 'b', label='Fit') # 회귀선을 파란색으로 표시
plt.title('키(height) 선 적합도') # 서브플롯의 제목 설정
# x, y축 레이블을 설정
plt.xlabel('height')
plt.ylabel('weight')
plt.legend() # 범례 표시
# 두 번째 서브플롯: 잔차도
plt.subplot(2, 2, 2) # 2x2 그리드에서 두 번째 위치에 서브플롯을 생성
residuals = fit.resid # 선형 회귀 모델의 잔차를 가져온다
plt.plot(height, residuals, 'o') # 잔차 ▸ 산점도로 표시
plt.title('키(height) 잔차도') # 서브플롯의 제목 설정
# x, y축 레이블을 설정
plt.xlabel('height')
plt.ylabel('Residuals')
# 세 번째 서브플롯: 잔차의 정규 확률도
plt.subplot(2, 2, 3) # 2x2 그리드에서 세 번째 위치에 서브플롯을 생성
stats.probplot(residuals, dist='norm', plot=plt) # 잔차의 정규 확률도 생성
plt.title('잔차 정규 확률도') # 서브플롯의 제목 설정.
# x, y축 레이블을 설정
plt.xlabel('Theoretical Quantiles')
plt.ylabel('Sample Quantiles')
# 플롯의 레이아웃을 자동으로 조정하여 요소들이 겹치지 않도록 한다.
plt.tight_layout()
#-------------------------------------------------------------------------
## 해석: 키(height)잔차도: 잔차 & 독립변수 값의 산점도
## 특별한 경향을 찾아볼 수 없다.
## 잔차 정규 확률도: 잔차의 정규성을 확인하기 위한 그래프
## 거의 직선의 형태를 이루므로, 잔차가 정규분포에 가깝다고 할 수 있다.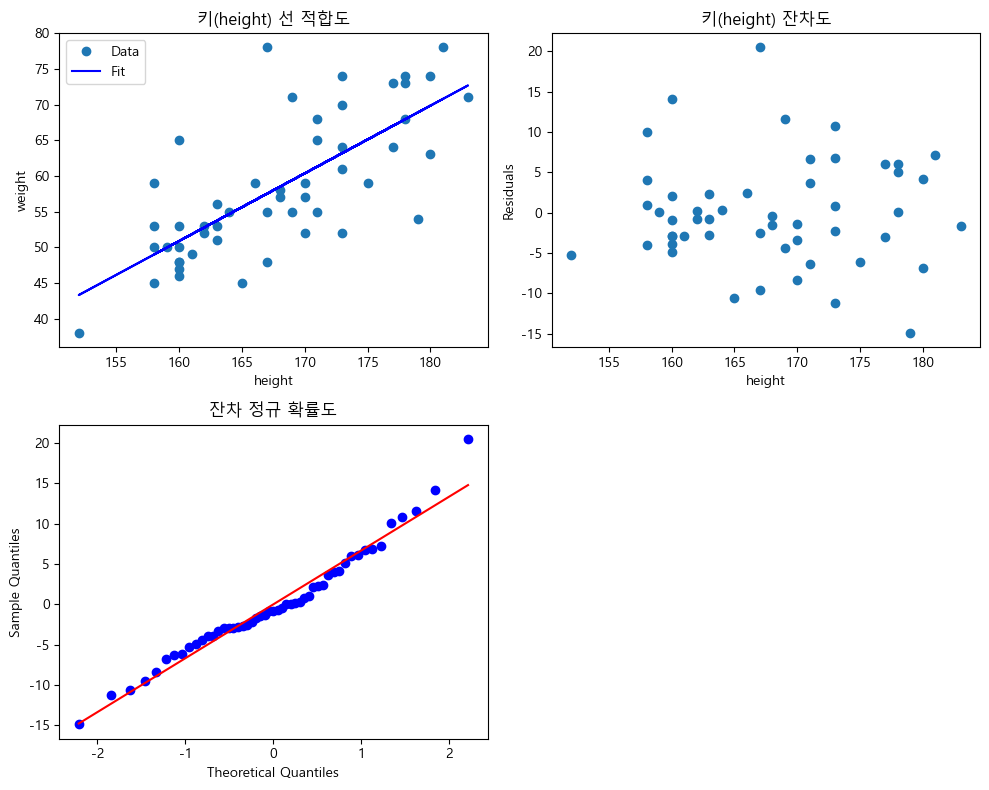
Mapo금빛나루 | | 공유 마당 (copyright.or.kr)
아래 첨자 / 첨자 기호 (piliapp.com)
Symbols (wumbo.net)
참고용 블로그: 작은 숫자 특수문자 첨자 및 분수숫자 모음
교제: 통계학: 파이썬을 이용한 분석
'2024 - 1학기 > 데이터분석입문' 카테고리의 다른 글
| 15장: 범주형 자료분석 (0) | 2024.08.12 |
|---|---|
| 14장: 분산분석 (2) | 2024.08.08 |
| 12장: 두 모집단의 비교 (2) | 2024.07.31 |
| 11장: 정규모집단에서의 추론 (0) | 2024.07.28 |
| 10장: 통계적 추론 (4) | 2024.07.25 |